데이터가 치우칠 때의 편차는 어떻게 할까
보통 대표치
전문가 이외의 사람이 파악하고 있는 통계학은 아마 평균치가 기준이 되고 있어, 거기로부터 분산등을 계산해, 하고 싶은 것의 단서로 한다고 생각합니다.
최근 일에서, 「어떤 분포를 모르는 때에는 어떻게 보면 좋을까」라고 의문으로 생각하는 일이 있었습니다. 예를 들어 실험 데이터를 볼 때 등, 통상은 정규 분포나 이항 분포 등의 평균이 가장 빈번한 것을 상정한다고 생각합니다. 그 전제가 없다면? 어떻게 데이터의 경향을 파악하면 좋을까요?
그런 것에 자세한 분 코멘트 주면 기쁩니다만, 나름대로 조금 생각해 보았습니다.
평균값이 실태를 잘 나타내지 않을 때
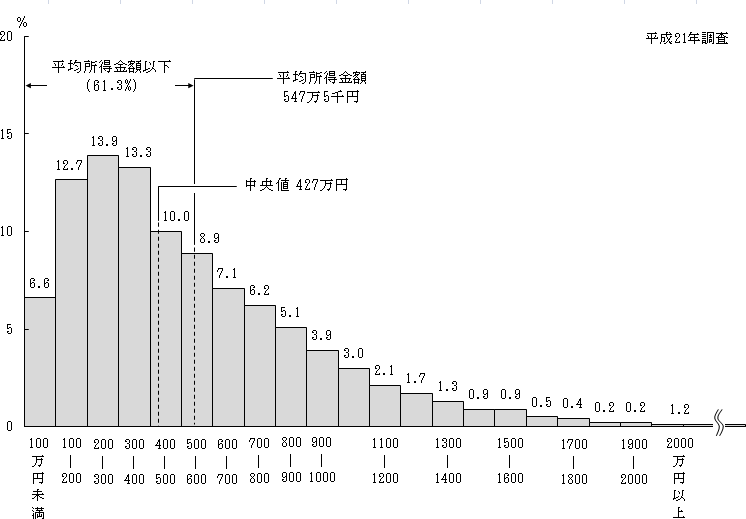
연봉의 이야기를 할 때 등은 종종 평균 연수수를 말하는 것이 많아, 「나 그렇게 받아라」라고 불평을 흘리는 사람이 많다고 생각합니다. 실제 일본의 연수 분포는 이렇게 되어 있다고 합니다.

헤세이 21년도 국민 생활 기초 조사
연수입이 아니어도 무언가의 통계 데이터가 이런 분포를 하고 있으면 평균에 그다지 의미를 느끼지 않지요. 어쨌든 최빈값을 곱해 중앙값이 데이터의 실태를 잘 표현한다고 생각합니다. 데이터의 값을 $x$, 평균을 $\bar{x}$로, 분산은 일반적으로 다음과 같이 정의됩니다.
$$\sigma^2=\frac{1}{N}\sum_{n=1}^{N}(x_n-\bar{x})^2$$
이것은 평균과의 차이를 편차로 정하고 있지 않습니까. 위와 같은 데이터에 대해 사용하려고 하면 분명히 부적절하죠? ?
최빈값을 기준으로 해보기
그럼 최빈치를 기준으로 해 볼까. 라고 생각 분산을 개조해 보았습니다.
$$\sigma'^2=\frac{1}{N}\sum_{n=1}^{N}(x_n-x_m)^2$$
$x_m$가 가장 빈번한 값입니다. 적당히 좋은 지표는 될 것 같지만 지금 이치핀과 오지 않네요. 데이터의 밑단이 널리 분포되어 있으면 좋지만, 연수입과 같이 한쪽이 꽉 막혀 있는 경우, 피크 위치가 왼쪽으로 갈수록 분산이 작아져 버릴 것 같습니다.
데이터 축 수정
또 하나 생각해 낸다(라고 하는 것보다 머리의 한쪽 구석에 있었다) 방법으로서 x축을 대수축등으로 해 그래프의 형태를 바꾸어 버리는 방법입니다.
단지 이것도 밑단의 데이터가 많이 있을 때밖에 유효하지 않습니다. 하한이 있을 때 드디어요. . .
뭔가 아이디어가 있으면
나는 이 근처의 지식이 기초 레벨 이하이므로 이런 데이터 해석의 방법이 있다든가 코멘트로 받을 수 있으면 고맙습니다. 분포가 불확실한 것을 어떻게 평가하는지, 앞으로 조금씩 조사해 가겠습니다.
Reference
이 문제에 관하여(데이터가 치우칠 때의 편차는 어떻게 할까), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다
https://qiita.com/tommyecguitar/items/d131351fb9f5326a860e
텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
연봉의 이야기를 할 때 등은 종종 평균 연수수를 말하는 것이 많아, 「나 그렇게 받아라」라고 불평을 흘리는 사람이 많다고 생각합니다. 실제 일본의 연수 분포는 이렇게 되어 있다고 합니다.
헤세이 21년도 국민 생활 기초 조사
연수입이 아니어도 무언가의 통계 데이터가 이런 분포를 하고 있으면 평균에 그다지 의미를 느끼지 않지요. 어쨌든 최빈값을 곱해 중앙값이 데이터의 실태를 잘 표현한다고 생각합니다. 데이터의 값을 $x$, 평균을 $\bar{x}$로, 분산은 일반적으로 다음과 같이 정의됩니다.
$$\sigma^2=\frac{1}{N}\sum_{n=1}^{N}(x_n-\bar{x})^2$$
이것은 평균과의 차이를 편차로 정하고 있지 않습니까. 위와 같은 데이터에 대해 사용하려고 하면 분명히 부적절하죠? ?
최빈값을 기준으로 해보기
그럼 최빈치를 기준으로 해 볼까. 라고 생각 분산을 개조해 보았습니다.
$$\sigma'^2=\frac{1}{N}\sum_{n=1}^{N}(x_n-x_m)^2$$
$x_m$가 가장 빈번한 값입니다. 적당히 좋은 지표는 될 것 같지만 지금 이치핀과 오지 않네요. 데이터의 밑단이 널리 분포되어 있으면 좋지만, 연수입과 같이 한쪽이 꽉 막혀 있는 경우, 피크 위치가 왼쪽으로 갈수록 분산이 작아져 버릴 것 같습니다.
데이터 축 수정
또 하나 생각해 낸다(라고 하는 것보다 머리의 한쪽 구석에 있었다) 방법으로서 x축을 대수축등으로 해 그래프의 형태를 바꾸어 버리는 방법입니다.
단지 이것도 밑단의 데이터가 많이 있을 때밖에 유효하지 않습니다. 하한이 있을 때 드디어요. . .
뭔가 아이디어가 있으면
나는 이 근처의 지식이 기초 레벨 이하이므로 이런 데이터 해석의 방법이 있다든가 코멘트로 받을 수 있으면 고맙습니다. 분포가 불확실한 것을 어떻게 평가하는지, 앞으로 조금씩 조사해 가겠습니다.
Reference
이 문제에 관하여(데이터가 치우칠 때의 편차는 어떻게 할까), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다
https://qiita.com/tommyecguitar/items/d131351fb9f5326a860e
텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
또 하나 생각해 낸다(라고 하는 것보다 머리의 한쪽 구석에 있었다) 방법으로서 x축을 대수축등으로 해 그래프의 형태를 바꾸어 버리는 방법입니다.
단지 이것도 밑단의 데이터가 많이 있을 때밖에 유효하지 않습니다. 하한이 있을 때 드디어요. . .
뭔가 아이디어가 있으면
나는 이 근처의 지식이 기초 레벨 이하이므로 이런 데이터 해석의 방법이 있다든가 코멘트로 받을 수 있으면 고맙습니다. 분포가 불확실한 것을 어떻게 평가하는지, 앞으로 조금씩 조사해 가겠습니다.
Reference
이 문제에 관하여(데이터가 치우칠 때의 편차는 어떻게 할까), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다
https://qiita.com/tommyecguitar/items/d131351fb9f5326a860e
텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
Reference
이 문제에 관하여(데이터가 치우칠 때의 편차는 어떻게 할까), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://qiita.com/tommyecguitar/items/d131351fb9f5326a860e텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
