업무 기회에 따라 사이트를 검색하다.
28214 단어 tutorialpythonbeginnerscodenewbie
오늘 저는 여러분과 제가 전자상거래 사이트를 긁은 후의 경험을 공유하고 싶습니다. 이 사이트의 이름은 Zomato입니다.내가 이 사이트를 긁어 현실 세계를 실천하는 상황에서 나는 아이디어를 얻은 후에 업무가 제공하는 UpWork를 보았다.
작업 설명:
이 고객은 Zomato 사이트에서 호주의 멜버른의 일부 유형에서 상업 정보를 얻을 것을 요구한다.종류는 카페, 중국식, 만두, 프랑스식 등이 있다.모든 데이터는 스프레드시트에 삽입해야 합니다.
고객이 수집하고자 하는 데이터입니다.

이 글에서, 나는 이 일을 완성하는 데 가장 낮은 요구를 알려주려고 한다. 더 많은 것을 개발할 수 있거나, 아니면 나를 볼 수 있다GitHub.
뭐 공부 해요?
주로 데이터를 캡처하여 거의 항상 HTTP 요청을 보내고 응답을 확인합니다.필요한 라이브러리는
request 및 beautifulsoup4 입니다.어떻게 설치합니까?
pip 명령을 사용하여 라이브러리를 설치하려면:
pip install requests pip install beautifulsoup4 1단계.나는python 파일을 만들어서main이라고 명명했습니다.파일의 맨 위에 라이브러리를 가져왔습니다.
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.zomato.com/melbourne/restaurants/cafes')
print(res.status_code)
# 403
requests, 내 클래스:I:"헤이, 형님, 저
get 화물 괜찮아요?"사이트: "당신의 상태 코드를 먼저 보겠습니다. 403입니다. 당신이 그것을 원한다는 것을 알지만, 당신은 그것을 가질 수 없습니다."
기다리다뭐 공부 해요?내 여행에서, 이것은 내가 처음으로 403을 상태 코드로 얻은 것이다.내가 원하는 것은 200이다. 이것은 성공을 의미한다.
나는 인터넷에서 해결 방안을 찾으려고 시도했는데, 다행히도 내가 찾았다.내 코드는 "서버와 네트워크 쌍방이 응용 프로그램을 식별할 수 있도록 하는 특징 문자열"이라는
User-Agent 이 필요합니다. 자세한 내용은 이 link 를 참조하십시오.나의 이해에 따르면, 내가 이 사이트를 요청하려고 할 때, 그것은 내가 제기한 요청을 식별할 수 없지만, 나를 들어가게 하지 않기 때문에, 나는 코드에 위장을 추가해야 한다.이것이 바로
User-Agent 한 일이다.Zomato 사이트의 측면에서 볼 때, 나의 코드는 브라우저와 같다.그래서 내 코드는 지금 이렇게 보인다.
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.zomato.com/melbourne/restaurants/cafes', headers={'User-Agent': 'Mozilla/5.0'})
print(res.status_code)
# 200
3단계.대문이 열렸습니다. Beautiful Soup으로 데이터를 수집할 때가 되었습니다.네, 이 코드를 썼습니다.
soup = BeautifulSoup(res.text, 'html.parser')
print(soup)
# <!DOCTYPE html>
# <html lang="en" prefix="og: http://ogp.me/ns#">
# ...
# </html>
res.text → 위의 요청(2단계)에서 HTML을 텍스트로 사용하고 싶습니다.html.parser → python이 가지고 있는 해상도 라이브러리입니다.해상도에 관해서는 table 를 보실 수 있습니다.저거 뭐 하는 거야?이 단계는 요리 텍스트가 포함된 HTML 태그를 검색하는 데 사용됩니다.
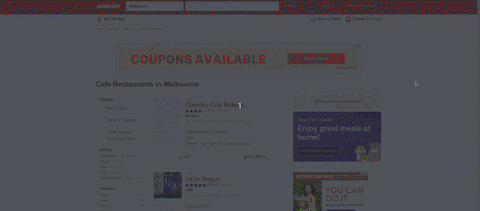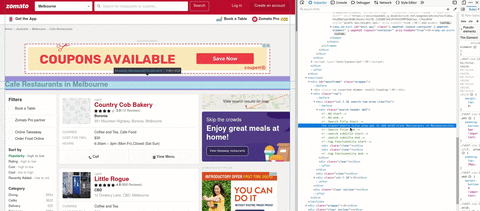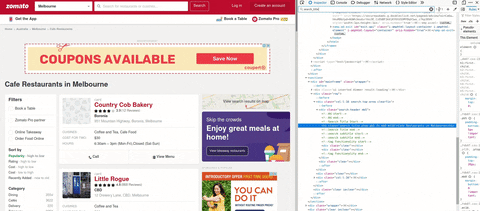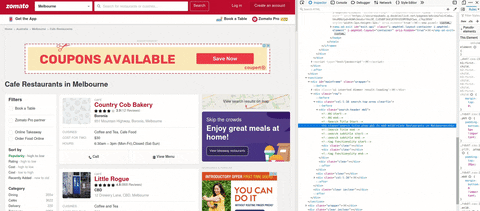
gif에서 요리가 포함된 검색 라벨을 볼 수 있습니다.태그
h1 에는 몇 가지 클래스 이름이 있습니다.inspect 요소 위에서, 나는 HTML을 검색하고 클래스를 복사해서 몇 개의 클래스가 같은 이름을 가지고 있는지 확인합니다.사용
search_title에는 일치하는 항목이 하나밖에 없습니다. 사용mb0에는 8개의 일치하는 항목이 있습니다.그래서 이 단계에서 나는 search_title 요리를 찾았다.cuisine = soup.find('h1', class_='search_title').text
print(cuisine)
# Cafe Restaurants in Melbourne
find (자세한 내용은 link 를 클릭하십시오.괄호에는 레이블의 이름h1, 속성class 및 이름search_title이 있습니다.class 뒤에 밑줄을 추가하는 것을 잊지 마십시오. 밑줄을 치지 않으면python에도 이 키워드가 있기 때문에 오류가 발생합니다.마지막 부분의
text 에 관해서는 필요한 태그 사이의 텍스트를 얻기 위한 것입니다.만약 네가 그것을 쓰지 않는다면, 반응은 이렇게 될 것이다.결과에는 태그가 포함됩니다.# <h1 class="search_title ptop pb5 fn mb0 mt10">
# Cafe Restaurants in Melbourne
# </h1>
아...이 문서를 작성할 때 다음 그림과 같이 페이지가 나타납니다.

나머지 값을 계속 추출합시다.기본적으로 절차는 요리를 추출하는 것과 같다.나는 단지 텍스트 위치를 찾아 표시와 클래스 이름을 전달할 수 있을 뿐이다.
조직의 경우:
organisation = soup.find('a', class_='result-title').text
print(organisation)
# Country Cob Bakery
asso_cuisine = soup.find('span', class_='col-s-11 col-m-12 nowrap pl0').text
print(asso_cuisine)
# Coffee and Tea, Cafe Food
고객이 제공한 견본을 보았을 때 위치와 주소는 같은 위치에 있습니다.우선, 나는 텍스트를 얻으려고 한다.
test = soup.find('div', class_='search-result-address').text
print(test)
# 951 Mountain Highway, Boronia, Melbourne

이미지 Y입니다.
성급 이하에는 고객이 원하는 위치가 있습니다.그래서 나는 주소의 같은 줄에서 위치를 얻을 필요가 없다.이때 나는 "가장 중요한 것은 내가 고객이 원하는 것을 제공할 수 있다는 것이다."라고 생각한다.
위치를 잡는 방법을 찾았습니다.곧, 나는 위치를 포함하는 라벨을 검색한 후에 텍스트를 얻었다.
위치:
location = soup.find('a', class_='search_result_subzone').text
print(location)
# Boronia
나는 내가 정규 표현식에 관한 책을 읽은 것을 기억한다. 그것은 내가 필요로 하는 것처럼 보이지만, 나는 여전히 잘 모른다.나는 인터넷에서 그것을 검색하려고 시도했다. 나는 대략
split() 을 찾았다.처음에 나는 split()이 정규 표현식의 일부분이라고 생각했지만, 그것은 아니었다.split() 문자열을 부분적으로 나누고 목록으로 되돌리는 데 사용됩니다.str.split([separator [, maxsplit]])
split 공백 (공간, 줄 바꿈 등) 은 구분자로 간주됩니다 link.네, 알겠습니다. 하지만 또 다른 곤혹이 생겼습니다. 저는 무엇을 구분표로 해야 합니까?
Y 이미지를 다시 한 번 보겠습니다. 주소는 앞에 있는 쉼표(,) 뒤에 공백과 위치입니다.→ 멜버른 볼로니아 산악 도로 951번지.마지막으로, 나는 그것들을 구분자로 사용하려고 시도했다.
주소:
address = soup.find('div', class_='search-result-address').text
separator = f', {location}'
address = address.split(separator)
print(address)
# [' 951 Mountain Highway', ', Melbourne']
print(address[0])
# 951 Mountain Highway
휴대폰:
phone = soup.find('a', class_='res-snippet-ph-info')['data-phone-no-str']
print(phone)
# 03 9720 2500
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.zomato.com/melbourne/restaurants/cafes', headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(res.text, 'html.parser')
cuisine = soup.find('h1', class_='search_title').text
organisation = soup.find('a', class_='result-title').text
asso_cuisine = soup.find('span', class_='col-s-11 col-m-12 nowrap pl0').text
location = soup.find('a', class_='search_result_subzone').text
address = soup.find('div', class_='search-result-address').text
test = soup.find('div', class_='search-result-address').text
phone = soup.find('a', class_='res-snippet-ph-info')['data-phone-no-str']
separator = f', {location}'
address = address.split(separator)
address = address[0]
import csv
# Create csv file
writer = csv.writer(open('./result.csv', 'w', newline='')) # method w -> write
headers = ['Cuisine', 'Assosiation Cuisine', 'Organisation', 'Address', 'Location', 'Phone']
writer.writerow(headers)
open() 함수가 결과를 열 것이라는 것을 안다.csv, 그러나 나머지는 csv.writer()의 일부분이라고 생각합니다.그러나 나는 왜 나의 뇌가 주의력을 집중할 수 없는지 모르겠다open()는 함수이다.csv.writer()의 일부가 아니다.open() 기능 이해우선 csv 파일의 이름을 씁니다. w write 방법입니다.문서에 따라 newline 일반적인 줄 바꿈 문자 모드를 제어하는 데 사용됩니다. (텍스트 모드에만 적용됩니다.)None,,\n, r 및\r\n일 수 있습니다. 참조linkcsv.writer 사용자 데이터를 구분자가 있는 문자열로 변환하고 writer.writerow() 한 번에 한 줄에 기록합니다.→ link # Add the value to csv file
writer = csv.writer(open('./result.csv', 'a', newline='', encoding='utf-8')) # method a -> append
data = [cuisine, asso_cuisine, organisation, address, location, phone]
writer.writerow(data)
a, a이 추가되었다는 점이다.이것 괜찮아요?→ link 최종 코드는 다음과 같습니다.
import csv
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.zomato.com/melbourne/restaurants/cafes', headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(res.text, 'html.parser')
cuisine = soup.find('h1', class_='search_title').text
organisation = soup.find('a', class_='result-title').text
asso_cuisine = soup.find('span', class_='col-s-11 col-m-12 nowrap pl0').text
location = soup.find('a', class_='search_result_subzone').text
address = soup.find('div', class_='search-result-address').text
test = soup.find('div', class_='search-result-address').text
phone = soup.find('a', class_='res-snippet-ph-info')['data-phone-no-str']
separator = f', {location}'
address = address.split(separator)
address = address[0]
writer = csv.writer(open('./result.csv', 'w', newline='')) # method w -> write
headers = ['Cuisine', 'Assosiation Cuisine', 'Organisation', 'Address', 'Location', 'Phone']
writer.writerow(headers)
writer = csv.writer(open('./result.csv', 'a', newline='', encoding='utf-8')) # method a -> append
data = [cuisine, asso_cuisine, organisation, address, location, phone]
writer.writerow(data)
그러나 이 문장에서 나는 내가 처음부터 시작한 여정을 공유하고 싶다. 이 문장을 너무 길게 읽지 않도록.아마도 다음 문장에서 나는 나의 여정을 계속 공유할 것이다.읽어주셔서 감사합니다.
P, 부끄러워하지 말고 질문하세요. 만약 무슨 오류(코드나 나의 해석)가 발견되면 아래 댓글에서 알려주세요.미리 감사합니다.
Reference
이 문제에 관하여(업무 기회에 따라 사이트를 검색하다.), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://dev.to/ilhamday/my-first-journey-scrape-website-based-on-upwork-job-offer-1-od2텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
