파이썬 슬라이드 종합 안내
29278 단어 beginnerspythonprogramming
strs 또는 lists)를 슬라이스할 수 있습니다.예:my_list = [1,2,3]
print(my_list[0]) # 1
my_string = "Python"
print(my_string[0]) # P
[과 ])를 사용하여 여러 부분의 대상을 분해할 수 있는 단일 요소를 사용합니다.그러나 이러한 꺾쇠 괄호 안에는 단일 요소에만 액세스하는 것이 아닙니다.
음색인
Python에서 마이너스 인덱스를 사용할 수 있음을 이미 알고 계실 수도 있습니다. 예를 들어,
my_list = list("Python")
print(my_list[-1])
my_list[-1]은 목록의 마지막 원소를 나타내고 my_list[-2]은 마지막 원소를 나타낸다.결장.
목록에서 여러 요소를 검색하려면 어떻게 해야 합니까?만약 네가 처음부터 끝까지 원한다면, 마지막 하나를 제외하고는.파이썬에서 문제 없음:
my_list = list("Python")
print(my_list[0:-1])
0, 2 등을 원한다면 어떻게 해야 합니까?이를 위해 우리는 첫 번째 원소에서 마지막 원소까지 필요하지만, 두 번째 원소는 건너뛰어야 한다.우리는 이렇게 쓸 수 있다.
my_list = list("Python")
print(my_list[0:len(my_list):2]) # ['P', 't', 'o']
slice 객체막후에서, 우리가
list류 대상을 방문하는 데 사용하는 단일 항목의 인덱스는 세 가지 값으로 구성되어 있다. 그것이 바로 (start, stop, step)이다.이러한 객체를 슬라이스 객체라고 하며 내장된 slice 함수를 사용하여 수동으로 만들 수 있습니다.우리는 두 가지가 확실히 같은지 확인할 수 있다.
my_list = list("Python")
start = 0
stop = len(my_list)
step = 2
slice_object = slice(start, stop, step)
print(my_list[start:stop:step] == my_list[slice_object]) # True
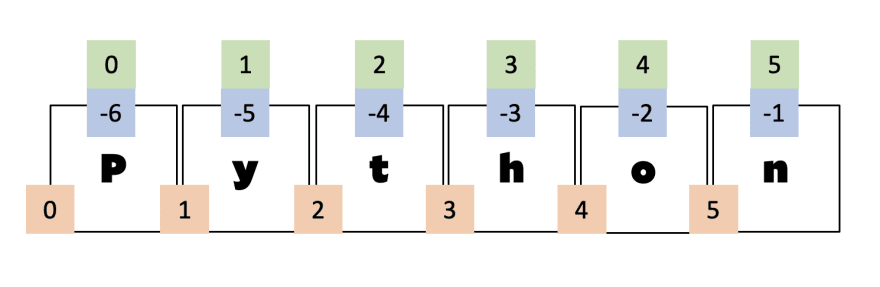
그림을 보십시오.알파벳
P은 우리 목록의 첫 번째 요소이기 때문에 0에 색인될 수 있습니다. (녹색 상자의 숫자 참조)목록의 길이는 6이기 때문에 첫 번째 요소도 -6 인덱스(파란색 상자에 마이너스 인덱스 표시)가 될 수 있다.녹색 및 파란색 상자의 숫자는 목록의 개별 요소를 나타냅니다.이제 주황색 네모난 상자의 숫자를 보세요.목록의 슬라이드 색인을 결정합니다.만약 우리가 슬라이드의
start과 stop을 사용한다면, 이 숫자 사이의 모든 요소는 슬라이드로 덮여 있다.예를 들면 다음과 같습니다."Python"[0:1] # P
"Python"[0:5] # Pytho
start값이 포함된 것이고 end값이 독점적인 것임을 기억하는 간단한 방법일 뿐이다.이성의 위약
대부분의 경우
slice부터 시작list0 구문에서 생략할 수 있습니다.print(my_list[0:-1] == my_list[:-1])
print(my_list[0:len(my_list):2] == my_list[::2])
1이 될 것이다.반대로 슬라이스 대상은
:으로 바뀝니다.None의 시작값은 정지값
None0단계그러나
len(list)이 음수이면 1s가step의 시작값은 정지값
None예를 들어, -1은 -len(list) - 1과 기술적으로 동일특수상황:던전
슬라이스는 다음과 같은 방법으로 바로 가기에 사용할 수 있는 특수한 경우가 있습니다.
기본값인
"Python"[::-1]만 사용하는 경우 동일한 항목을 제공합니다.my_list = list("Python")
my_list_2 = my_list[:]
print(my_list==my_list_2)
"Python"[-1:-7:-1] 내장 장치를 사용하여 다음을 확인할 수 있습니다.print(id(my_list))
print(id(my_list_2))
my_list[:]만 사용하여 시퀀스 복사본을 만들 수 있습니다.다음은 차이점을 설명하는 두 개의 코드 세그먼트입니다.
a = list("Python")
b = a
a[-1] = "N"
print(a)
# ['P', 'y', 't', 'h', 'o', 'N']
print(b)
# ['P', 'y', 't', 'h', 'o', 'N']
a = list("Python")
b = a[:]
a[-1] = "N"
print(a)
# ['P', 'y', 't', 'h', 'o', 'N']
print(b)
# ['P', 'y', 't', 'h', 'o', 'n']
예.
몇 가지 일반적인 예:
용례
파이썬 코드
각 요소
슬라이스가 없거나
id으로 복제초당 원소
[:](짝수) 또는 [:](홀수)모든 원소는 첫 번째를 제외하고는
[::2]마지막 요소를 제외한 모든 요소[1::2]첫 번째와 마지막 하나를 제외한 모든 원소[1:]모든 원소의 순서는 상반된다[:-1]첫 번째 원소와 마지막 원소를 제외하고는 모든 원소의 순서가 상반된다[1:-1]두 번째 원소는 첫 번째 원소와 마지막 원소의 순서가 상반된다[::-1]
숙제
p = list("Python")
# ['P', 'y', 't', 'h', 'o', 'n']
p[1:-1]
# ['y', 't', 'h', 'o']
p[1:-1] = 'x'
print(p)
['P', 'x', 'n']
p = list("Python")
p[1:-1] = ['x'] * 4
p
# ['P', 'x', 'x', 'x', 'x', 'n']
순환을 이해하다
파이톤의 각
[-2:0:-1] 대상은 모두 [-2:0:-2] 방법이 있다.이 방법은 한 쌍(slice, indices, start, end)으로 되돌아갈 것입니다. 이 방법으로 슬라이스 작업에 해당하는 순환을 재구성할 수 있습니다.복잡하게 들려요?자세히 살펴보겠습니다.
다음 순서로 시작하겠습니다.
sequence = list("Python")
step을 살펴보겠습니다.my_slice = slice(None, None, 2) # equivalent to `[::2]`.
[::2]s이기 때문에 절편 대상은 서열의 길이에 따라 실제 None값을 계산해야 한다.따라서 색인 3원조를 얻기 위해 우리는 길이를 index 방법에 전달해야 한다. 아래와 같다.indices = my_slice.indices(len(sequence))
indices을 제공할 것이다.이제 우리는 이렇게 순환을 다시 만들 수 있다.sequence = list("Python")
start = 0
stop = 6
step = 2
i = start
while i != stop:
print(sequence[i])
i = i+step
(0, 6, 2) 자체와 같은 목록 요소에 접근할 것입니다.자신의 종류를 절단할 수 있게 하다
자신의 클래스에서 슬라이드 대상을 사용할 수 없으면 파이톤은 파이톤이 아닙니다.
더 좋은 것은 슬라이스가 수치일 필요가 없다는 것이다.우리는 알파벳 색인에 따라 슬라이드를 할 수 있는 주소록을 만들 수 있다.
import string
class AddressBook:
def __init__(self):
self.addresses = []
def add_address(self, name, address):
self.addresses.append((name, address))
def get_addresses_by_first_letters(self, letters):
letters = letters.upper()
return [(name, address) for name, address in self.addresses if any(name.upper().startswith(letter) for letter in letters)]
def __getitem__(self, key):
if isinstance(key, str):
return self.get_addresses_by_first_letters(key)
if isinstance(key, slice):
start, stop, step = key.start, key.stop, key.step
letters = (string.ascii_uppercase[string.ascii_uppercase.index(start):string.ascii_uppercase.index(stop)+1:step])
return self.get_addresses_by_first_letters(letters)
address_book = AddressBook()
address_book.add_address("Sherlock Holmes", "221B Baker St., London")
address_book.add_address("Wallace and Gromit", "62 West Wallaby Street, Wigan, Lancashire")
address_book.add_address("Peter Wimsey", "110a Piccadilly, London")
address_book.add_address("Al Bundy", "9764 Jeopardy Lane, Chicago, Illinois")
address_book.add_address("John Dolittle", "Oxenthorpe Road, Puddleby-on-the-Marsh, Slopshire, England")
address_book.add_address("Spongebob Squarepants", "124 Conch Street, Bikini Bottom, Pacific Ocean")
address_book.add_address("Hercule Poirot", "Apt. 56B, Whitehaven Mansions, Sandhurst Square, London W1")
address_book.add_address("Bart Simpson", "742 Evergreen Terrace, Springfield, USA")
print(string.ascii_uppercase)
print(string.ascii_uppercase.index("A"))
print(string.ascii_uppercase.index("Z"))
print(address_book["A"])
print(address_book["B"])
print(address_book["S"])
print(address_book["A":"H"])
해석하다
slice 방법 def get_addresses_by_first_letters(self, letters):
letters = letters.upper()
return [(name, address) for name, address in self.addresses if any(name.upper().startswith(letter) for letter in letters)]
get_addresses_by_first_letters에 속하는 모든 주소를 필터합니다. 이 주소는 name 매개 변수의 모든 자모로 시작합니다.우선, 우리는 함수가 대소문자를 구분하지 않도록 letters을 대문자로 변환할 것이다.그리고 우리는 내부 letters 목록에서 list comprehension을 사용한다.만약 제공된 모든 알파벳이 addresses 값에 대응하는 첫 번째 알파벳과 일치한다면 목록의 조건은 이해를 테스트할 것입니다.name 방법__getitem__ 대상을 절단할 수 있도록 파이톤을 덮어쓰는 신기한 쌍밑줄 긋기 방법 AddressBook이 필요합니다. def __getitem__(self, key):
if isinstance(key, str):
return self.get_addresses_by_first_letters(key)
if isinstance(key, slice):
start, stop, step = key.start, key.stop, key.step
letters = (string.ascii_uppercase[string.ascii_uppercase.index(start):string.ascii_uppercase.index(stop)+1:step])
return self.get_addresses_by_first_letters(letters)
__getitem__인지 확인합니다.만약 우리가 네모난 괄호 중의 단일 자모로 대상을 방문한다면, 이러한 상황이 나타날 것이다. str.우리는 알파벳으로 시작하는 모든 이름을 되돌려 줄 수 있다.흥미로운 것은
address_book["A"]이 key의 대상이다.예를 들어 slice과 같은 방문은 이 조건에 부합될 것이다.우선, 우리는 알파벳 순서에 따라
address_book["A":"H"]과 A 사이의 모든 알파벳을 식별한다.파이톤의 H 모듈은 string의 모든 (라틴) 자모를 보여 줍니다.우리는 주어진 자모 사이의 자모를 추출하기 위해 string.ascii_uppercase을 사용한다.두 번째 슬라이스 매개 변수 중 slice을 주의하십시오.이런 방식을 통해 우리는 마지막 편지가 배타적이지 않고 포용적일 것을 확보한다.우리가 서열 중의 모든 자모를 확정한 후에, 우리는
+1을 사용했고, 우리는 이미 토론을 한 적이 있다.이것은 우리가 원하는 결과를 주었다.
Reference
이 문제에 관하여(파이썬 슬라이드 종합 안내), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://dev.to/bascodes/a-comprehensive-guide-to-slicing-in-python-mko텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
