SQL Server 의 간단 한 검색 어 를 자세히 설명 합 니 다.
일부 원리 적 인 문장 원 에 대량의 글 이 있 는데 특히 색인 이라는 부분 에 대해 저도 많은 시간 을 들 여 공 부 를 했 습 니 다.색인 원 리 를 이해 하 는 것 은 조회 계획 과 성능 개선 에 큰 도움 이 되 었 습 니 다.우 리 는 일부 내용 만 요약 하고 정리 할 뿐 이 절 에서 우 리 는 SQL 에서 간단 한 조회 문 구 를 공부 하기 시 작 했 습 니 다.간단 한 내용,깊이 있 는 이해.
단순 검색 어
모든 복잡 한 문 구 는 간단 한 문구 로 구성 되 어 있 으 며 기본적으로 SELECT,FROM,WHERE,GROUP BY,HAVING,ORDER BY 등 으로 구성 되 어 있 으 며 물론 서술 어 등 도 포함 되 어 있다.예 를 들 어 우리 가 특정한 표 의 모든 데 이 터 를 조회 하려 고 할 때 우 리 는 다음 과 같이 진행 할 것 이다.
SELECT * FROM TABLE여기 서 검색 하면 SELECT 부터 시작 하 는 거 아니에요?우 리 는 실제 생활 에서 예 를 들 어야 한다.만약 에 우리 가 채소 시장 에 가서 채 소 를 사 야 한다 면 미 나 리 를 사고 싶다.우 리 는 미나리 가 있 는 노점 에서 사 야 한다.즉,어디서 사 야 하 는 지,여기 서 우 리 는 상기 조회 데이터 의 순 서 는 먼저 FROM 다음 에 SELECT 가 되 어야 한 다 는 것 을 알 게 될 것 이다.SQL 2012 기초 튜 토리 얼 에서 자 구 를 열거 하 는 것 은 다음 과 같은 순서 로 논리 적 으로 처리 합 니 다.
FROM
WHERE
GROUP BY
HAVING
SELECT
ORDER BY
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numbers
FROM Sales.Orders
WHERE custid = '71'
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
ORDER BY empid, orderyear
FROM Sales.Orders
WHERE custid = 71
GROUP BY empid, YEAR(orderdate)
HAVING COUNT(*) > 1
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numberorders
ORDER BY empid, orderyear우 리 는 SQL 의 성능 문 제 를 이야기 하 는 글 을 많이 보 았 습 니 다.예 를 들 어 모든 데 이 터 를 조회 할 때 SELECT*가 아 닌 모든 열 을 열거 해 야 하기 때문에 본 시리즈 에서 저 는 성능 문 제 를 적당 하 게 이야기 할 것 입 니 다.예 를 들 어 본 절 에서 말 하고 자 하 는 SELECT 1 과 SELECT*의 성능 문제 등 입 니 다.
SELECT 1 과 SELECT*성능 검토
데이터베이스 에서 실행 계획 을 볼 때 우 리 는 보통[예상 되 는 실행 계획 표시]단축 키 를 클릭 합 니 다.여기 서 우 리 는 이것 이 예상 되 는 실행 계획 만 표시 되 어 있 기 때문에 정확 하지 않 습 니 다.그래서 실제 실행 계획 을 표시 하기 위해 서 우 리 는[실제 실행 계획 포함]을 시작 해 야 합 니 다.단축 키 는 Ctrl+M 입 니 다.이렇게 해야만 비교적 정확 한 집행 계획 을 얻 을 수 있다.다음 과 같다.

조회 방식 1(전체 표 조회)
USE TSQL2012
GO
IF EXISTS(
SELECT 1
FROM Sales.Orders)
SELECT 'SELECT 1'
GO
IF EXISTS(
SELECT *
FROM Sales.Orders)
SELECT 'SELECT *'
GO
검색 방식 2(색인 열 에서 조건 찾기)
우 리 는 어떤 열 에 색인 을 만 듭 니 다.
CREATE INDEX ix_shipname
ON Sales.Orders(shipname)
검색 계획 이 똑 같 음 을 표시 합 니 다.우 리 는 다시 다른 조회 방식 을 보 자.
조회 방식 3(집합 함수 사용)
USE TSQL2012
GO
IF (
SELECT 1
FROM Sales.Orders
WHERE shipname = 'Ship to 85-B') = 1
SELECT 'SELECT 1'
GO
IF (
SELECT COUNT(*)
FROM Sales.Orders
WHERE shipname = 'Ship to 85-B') = 1
SELECT 'SELECT *'
GO
조회 방식 4(집합 함수 Count 를 사용 하여 비 색인 열 에서 찾기)
USE TSQL2012
GO
IF (
SELECT COUNT(1)
FROM Sales.Orders
WHERE freight = '41.3400') = 1
SELECT 'SELECT 1'
GO
IF (
SELECT COUNT(*)
FROM Sales.Orders
WHERE freight = '41.3400') = 1
SELECT 'SELECT *'
GO
조회 방식 5(하위 조회)
우 리 는 하위 조회 에서 양자 의 성능 이 어떤 지 보 자.
USE TSQL2012
SELECT custid, companyname FROM Sales.Customers AS C
WHERE country = N'USA' AND
EXISTS (SELECT * FROM Sales.Orders AS O WHERE O.custid = C.custid)
GO
SELECT custid, companyname FROM Sales.Customers AS C
WHERE country = N'USA' AND
EXISTS (SELECT 1 FROM Sales.Orders AS O WHERE O.custid = C.custid)
조회 방식 6(보기 에서 조회)
SELECT 1 과 SELECT*의 성능 을 비교 하기 위해 보 기 를 만 듭 니 다.
USE TSQL2012
Go
CREATE VIEW SaleOdersView
AS
SELECT shipaddress,shipname,(SELECT unitprice FROM Sales.OrderDetails AS sod where sod.orderid = so.orderid) as tc3
FROM Sales.Orders AS so
GO
USE TSQL2012
SELECT 1 FROM dbo.SaleOdersView
go
SELECT * FROM dbo.SaleOdersView
go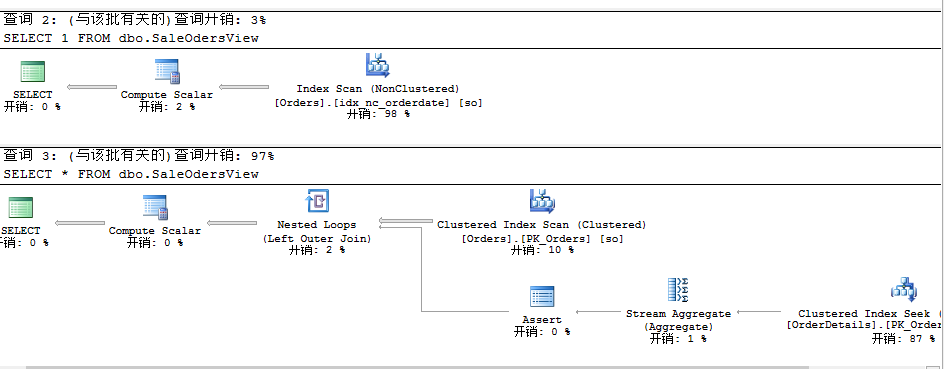
이때 우 리 는 상기 그림 을 통 해 보 기 를 이용 하여 조회 할 때 SELECT*의 성능 이 이렇게 저하 되 어 97%를 차지 하고 SELECT 1 은 3%에 불과 하 다 는 것 을 발견 했다.이것 은 왜 일 까?그 이 유 를 모 르 겠 습 니 다.그 이 유 를 잘 아 는 원우 들 이 댓 글 을 남 겨 합 리 적 인 설명 을 해 주 셨 으 면 좋 겠 습 니 다.
SELECT 모든 열 과 SELECT*성능 검토
지금까지 모든 튜 토리 얼 은 SELECT*성능 이 SELECT 의 모든 열 보다 낮 고 합 리 적 인 이 유 를 제시 해 왔 습 니 다.저도 그렇게 생각 했 지만 자 료 를 찾 아 학습 하 는 과정 에서 다음 과 같은 말 을 발 견 했 습 니 다.
I don't think there is any difference, as long as the SELECT 1/* is inside EXISTS, which really doesn't return any rows C it just returns boolean as soon as condition of the WHERE is checked.
I'm quite sure that the SQL Server Query Optimizer is smart enough not to search for the unneeded meta data in the case of EXISTS.
I agree that in all the other situations SELECT * shouldn't be used for the reasons Simon mentioned. Also, index usage wouldn't be optimal etc.
For me EXISTS (SELECT * ..) is the only place where I allow myself to write SELECT * in production code ;)총결산
이상 의 SELECT 1 과 SELECT*성능 에 대한 연 구 를 통 해 보기 에서 SELECT*를 이용 하여 성능 이 더욱 떨 어 지 는 동시에 SELECT*와 결합 하여 사용 하지 않도록 하 겠 습 니 다.저 는 SELECT 1 을 사용 하 는 경향 이 있다 고 결론 을 내 릴 수 있 지 않 습 니까?두 번 째 는 위 에서 제시 한 자 료 를 보 는 것 입 니 다.SELECT*Exist 에서 의 성능 은 일정한 SELECT 의 모든 열 과 같 지 않 습 니까?이것 은 제 가 의문 이 존재 하 는 두 가지 문제 입 니 다.제 가 의문 하 는 두 가지 문제 입 니까?구체 적 인 답 이 없고 응용 장면 을 봐 야 합 니까?그 응용 장면 은 또 어디 에 있 습 니까?전문 적 인 DBA 가 아니 고 SQL 에 대한 연구 도 깊 지 않 기 때문에 이 글 을 읽 는 독자 들 이 멋 진 대답 을 하 는 동시에 저 에 게 공부 도 하 게 해 주 기 를 바 랍 니 다.
이상 은 본 고의 모든 내용 입 니 다.본 고의 내용 이 여러분 의 학습 이나 업무 에 어느 정도 도움 이 되 기 를 바 랍 니 다.궁금 한 점 이 있 으 면 댓 글 을 남 겨 서 교류 할 수 있 고 저 희 를 많이 응원 해 주 셨 으 면 좋 겠 습 니 다!
이 내용에 흥미가 있습니까?
현재 기사가 여러분의 문제를 해결하지 못하는 경우 AI 엔진은 머신러닝 분석(스마트 모델이 방금 만들어져 부정확한 경우가 있을 수 있음)을 통해 가장 유사한 기사를 추천합니다:
깊이 중첩된 객체를 정확히 일치 검색 - PostgreSQL목차 * 🚀 * 🎯 * 🏁 * 🙏 JSON 객체 예시 따라서 우리의 현재 목표는 "고용주"사용자가 입력한 검색어(이 경우에는 '요리')를 얻고 이 용어와 정확히 일치하는 모든 사용자 프로필을 찾는 것입니다. 즐거운 ...
텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
CC BY-SA 2.5, CC BY-SA 3.0 및 CC BY-SA 4.0에 따라 라이센스가 부여됩니다.
좋은 웹페이지 즐겨찾기
