redis 해시 타 입동력 노드 자바 대학 정리
상용 방법
하나의 데이터 구조 라면 가장 기본 적 인 것 은 CURD,redis 의 insert 와 update 입 니 다.영원히 set 로 대체 해 야 합 니 다.예 를 들 어 아래 의 Hset,다음 과 같은 그림 입 니 다.

자바 의 클래스 와 방법 처럼 어떤 인 자 를 전달 하 는 지 알 면 됩 니 다.예 를 들 어 HSet 과 같은 형식 은 다음 과 같 습 니 다.

다음은 제 가 CentOS 에서 조작 해 볼 게 요.
[administrator@localhost redis-3.0.5]$ src/redis-cli
.0.0.1:6379> clear
.0.0.1:6379> hset person name jack
(integer) 1
.0.0.1:6379> hset person age 20
(integer) 1
.0.0.1:6379> hset person sex famale
(integer) 1
.0.0.1:6379> hgetall person
) "name"
) "jack"
) "age"
) "20"
) "sex"
) "famale"
.0.0.1:6379> hkeys person
) "name"
) "age"
) "sex"
.0.0.1:6379> hvals person
) "jack"
) "20"
) "famale"
.0.0.1:6379>
Map<String,String> person=new HashMap<string,string>();
person.Add("name","jack");
....2.탐색 원리
hash 의 소스 코드 는 dict.h 소스 코드 에 있 습 니 다.다음 과 같 습 니 다.
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new 0. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
typedef struct dictIterator {
dict *d;
long index;
int table, safe;
dictEntry *entry, *nextEntry;
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint;
} dictIterator;dict 구조
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;<1> dictType *type
그것 의 유형 은 dict Type 임 을 볼 수 있 습 니 다.위 에서 도 볼 수 있 습 니 다.이것 은 매 거 진 구조 정의 가 있 습 니 다.다음 과 같 습 니 다.
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;<2> dictht ht[2]
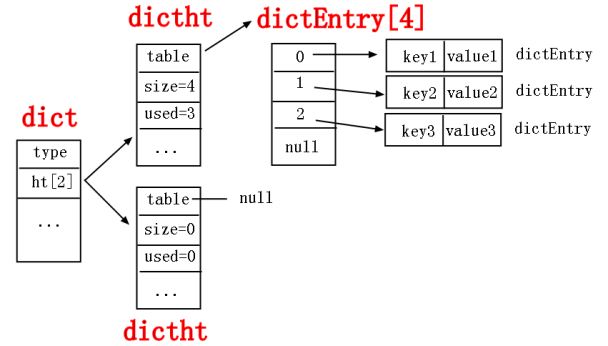
왜 이 속성 이 2 개의 크기 의 배열 인지 의문 이 들 수 있 습 니 다.사실은 ht[0]를 사용 하고 있 습 니 다.ht[1]는 hash 표를 확장 할 때 임시 저장 배열 입 니 다.이것 도 이상 하고 정교 합 니 다.redis 는 왜 그 랬 습 니까?곰 곰 이 생각해 보면 용량 을 늘 리 는 데 는 두 가지 방법 이 있 는데,한꺼번에 용량 을 늘 리 거나 점진 적 으로 용량 을 늘 리 는 것 이 무슨 뜻 인지 알 수 있 을 것 이다.바로 제 가 용량 을 확대 하 는 동시에 전단 의 CURD 에 영향 을 주지 않 습 니 다.저 는 데 이 터 를 ht[0]에서 ht[1]로 천천히 옮 겼 습 니 다.그리고 rehashindex 는 이전 상황 을 기록 하고 모든 이전 이 완 료 된 후에 ht[1]를 ht[0]로 바 꾸 었 습 니 다.이렇게 간단 합 니 다.
dicth 구조
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;위의 이 구조 체 에서 당신 은 매우 중요 한 속성 을 볼 수 있 습 니 다. dictEntry**table,그 중에서 table 은 하나의 배열 입 니 다.배열 유형 은 dictEntry 입 니 다.하나의 배열 인 이상 뒤의 세 가지 속성 을 이해 할 수 있 습 니 다.size 는 배열 의 크기 입 니 다.size mask 는 배열 의 모델 링 과 관련 되 고 used 는 배열 에서 사용 한 크기 를 기록 합 니 다.지금 우 리 는 dictEntry 라 는 배열 의 실체 유형 에 주 의 를 기울 입 니 다.
dictEntry 구조
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;첫 번 째 는: *key:이것 이 바로 hash 표 의 key 입 니 다.
두 번 째 는: 유 니 온 의*val 은 hash 의 value 입 니 다.
세 번 째 는: *next 는 hash 충돌 을 방지 하기 위 한 체인 수단 입 니 다.
위 에서 설명 한 것 을 정리 하면 다음 과 같은 hash 구조 도 를 그 릴 수 있 습 니 다.
이 내용에 흥미가 있습니까?
현재 기사가 여러분의 문제를 해결하지 못하는 경우 AI 엔진은 머신러닝 분석(스마트 모델이 방금 만들어져 부정확한 경우가 있을 수 있음)을 통해 가장 유사한 기사를 추천합니다:
Redis 해시에 대한 완벽한 가이드변경 가능하므로 필요에 따라 쉽게 변경하고 업데이트할 수 있습니다. Redis 해시는 구조가 평평하므로 JSON에서와 같이 여러 수준을 가질 수 없습니다. redis 해시의 명명 규칙은 hash:key 로 입력되므로...
텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
CC BY-SA 2.5, CC BY-SA 3.0 및 CC BY-SA 4.0에 따라 라이센스가 부여됩니다.
좋은 웹페이지 즐겨찾기
