PostgreSQL 튜 토리 얼(4):데이터 형식 상세 설명
다음은 PostgreSQL 이 지원 하 는 수치 형식의 목록 과 간단 한 설명 입 니 다.
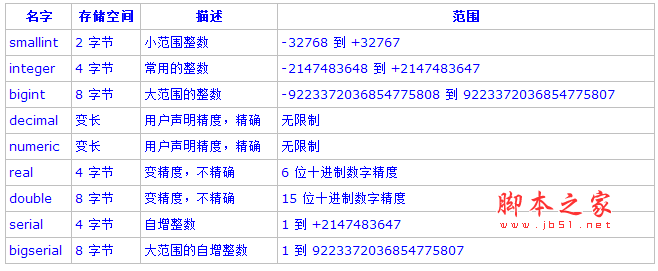
1.정수 유형:
유형 smallint,integer,bigint 는 각종 범 위 를 저장 하 는 것 은 모두 숫자의 수 이 며,즉 소수 부분의 숫자 가 없다.범 위 를 초과 한 수 치 를 저장 하려 고 시도 하면 오류 가 발생 할 수 있 습 니 다.자주 사용 하 는 유형 은 integer 입 니 다.범위,저장 공간 과 성능 사이 의 최 적 균형 을 제공 하기 때 문 입 니 다.보통 디스크 공간 이 부족 할 때 만 smallint 를 사용 합 니 다.integer 의 범위 가 부족 할 때 만 bigint 를 사용 합 니 다.전자(integer)가 훨씬 빠 르 기 때 문 입 니 다.
2.임 의 정밀도 수치:
유형 numeric 는 최대 1000 비트 의 정밀도 의 숫자 를 저장 하고 정확하게 계산 할 수 있다.따라서 화폐 금액 과 기타 요구 에 따라 정확 한 수량 을 계산 하 는 데 매우 적합 하 다.그러나 numeric 유형의 산술 연산 은 정수 유형 이나 부동 소수점 유형 보다 훨씬 느리다.
numeric 필드 의 최대 정밀도 와 최대 비례 는 모두 설정 할 수 있 습 니 다.numeric 형식의 필드 를 설명 하려 면 다음 문법 을 사용 하 십시오.
NUMERIC(precision,scale)
현재 PostgreSQL 버 전에 서 는 decimal 과 numeric 가 같은 효 과 를 가지 고 있 습 니 다.
3.부동 소수점 유형:
데이터 형식 real 과 double 은 부정 확 하고 희생 정밀도 가 있 는 디지털 형식 입 니 다.정확 하지 않 은 것 은 일부 수치 가 내부 형식 으로 정확하게 변환 되 지 않 고 비슷 한 형식 으로 저장 되 어 있 음 을 의미 하기 때문에 저장 한 후에 데 이 터 를 인쇄 하면 약간의 결함 을 나 타 낼 수 있다.
4.시리 얼(번호)종류:
serial 과 bigserial 유형 은 진정한 유형 이 아니 라 표 에 유일한 표 지 를 설정 하기 위 한 개념 적 편의 일 뿐이다.
CREATE TABLE tablename (
colname SERIAL
);
CREATE SEQUENCE tablename_colname_seq;
CREATE TABLE tablename(
colname integer DEFAULT nextval('tablename_colname_seq') NOT NULL
);
또 다른 설명 이 필요 한 것 은 serial 형식 으로 만 든 시퀀스 가 소속 필드 에서 삭 제 될 때 이 시퀀스 도 자동 으로 삭제 되 지만 다른 경우 에는 삭제 되 지 않 습 니 다.따라서 같은 시퀀스 발생 기 를 사용 하여 몇 필드 에 데 이 터 를 동시에 제공 하려 면 독립 된 대상 으로 이 시퀀스 발생 기 를 만들어 야 합 니 다.
2.문자 형식:
다음은 PostgreSQL 이 지원 하 는 문자 형식의 목록 과 간단 한 설명 입 니 다.

SQL 은 두 가지 기본 적 인 문자 형식 을 정의 합 니 다.varchar(n)와 char(n)입 니 다.여기 n 은 정수 입 니 다.두 가지 유형 모두 최대 n 글자 길이 의 문자열 을 저장 할 수 있 습 니 다.이 유형의 필드 에 더 긴 문자열 을 저장 하려 고 하면 길이 가 초과 한 문자 가 모두 공백 이 아 닌 경우 이 문자열 은 최대 길이 로 절 단 됩 니 다.길이 설명 이 없 으 면 char 는 char(1)와 같 고 varchar 는 모든 길이 의 문자열 을 받 아들 일 수 있 습 니 다.
MyTest=> CREATE TABLE testtable(first_col varchar(2));
CREATE TABLE
MyTest=> INSERT INTO testtable VALUES('333'); -- , , 。
ERROR: value too long for type character varying(2)
-- , , , 。
MyTest=> INSERT INTO testtable VALUES('33 ');
INSERT 0 1
MyTest=> SELECT * FROM testtable;
first_col
-----------
33
(1 row)
MyTest=> select 1234::varchar(2);
varchar
---------
12
(1 row)
3.날짜/시간 유형:
다음은 PostgreSQL 이 지원 하 는 날짜/시간 형식의 목록 과 간단 한 설명 입 니 다.

1.날짜/시간 입력:
모든 날짜 나 시간의 텍스트 입력 은 하나의 텍스트 문자열 처럼 작은 따옴표 로 둘러싸 여야 합 니 다.
1).날짜:
다음은 합 법 적 인 날짜 형식 목록 입 니 다.

2).시간:
다음은 합 법 적 인 시간 형식 목록 입 니 다.

3).타임 스탬프:
타임 스탬프 형식의 유효한 입력 은 날짜 와 시간의 연결 로 이 루어 져 있 으 며,뒤에 선택 할 수 있 는 시간 대 를 따른다.따라서 1999-01-08 04:05:06 과 1999-01-08 04:05:06-8:00 은 모두 효과 적 인 수치 이다.
2.예시:
1).데 이 터 를 삽입 하기 전에 datestyle 시스템 변수의 값 을 먼저 봅 니 다.
MyTest=> show datestyle;
DateStyle
-----------
ISO, YMD
(1 row)
MyTest=> CREATE TABLE testtable (id integer, date_col date, time_col time, timestamp_col timestamp);
CREATE TABLE
MyTest=> INSERT INTO testtable(id,date_col) VALUES(1, DATE'01/02/03'); --datestyle YMD
INSERT 0 1
MyTest=> SELECT id, date_col FROM testtable;
id | date_col
----+------------
1 | 2001-02-03
(1 row)
MyTest=> set datestyle = MDY;
SET
MyTest=> INSERT INTO testtable(id,date_col) VALUES(2, DATE'01/02/03'); --datestyle MDY
INSERT 0 1
MyTest=> SELECT id,date_col FROM testtable;
id | date_col
----+------------
1 | 2001-02-03
2 | 2003-01-02
MyTest=> INSERT INTO testtable(id,time_col) VALUES(3, TIME'10:20:00'); -- 。
INSERT 0 1
MyTest=> SELECT id,time_col FROM testtable WHERE time_col IS NOT NULL;
id | time_col
----+----------
3 | 10:20:00
(1 row)
MyTest=> INSERT INTO testtable(id,timestamp_col) VALUES(4, DATE'01/02/03');
INSERT 0 1
MyTest=> INSERT INTO testtable(id,timestamp_col) VALUES(5, TIMESTAMP'01/02/03 10:20:00');
INSERT 0 1
MyTest=> SELECT id,timestamp_col FROM testtable WHERE timestamp_col IS NOT NULL;
id | timestamp_col
----+---------------------
4 | 2003-01-02 00:00:00
5 | 2003-01-02 10:20:00
(2 rows)
PostgreSQL 은 표준 SQL boolean 데이터 형식 을 지원 합 니 다.boolean 은 두 가지 상태 중 하나 만 있 을 수 있 습 니 다.진(True)이나 가짜(False)입 니 다.이 형식 은 바이트 하 나 를 차지 합 니 다.
"진짜"값 의 유효한 텍스트 값 은:
TRUE
't'
'true'
'y'
'yes'
'1'
FALSE
'f'
'false'
'n'
'no'
'0'
MyTest=> CREATE TABLE testtable (a boolean, b text);
CREATE TABLE
MyTest=> INSERT INTO testtable VALUES(TRUE, 'sic est');
INSERT 0 1
MyTest=> INSERT INTO testtable VALUES(FALSE, 'non est');
INSERT 0 1
MyTest=> SELECT * FROM testtable;
a | b
---+---------
t | sic est
f | non est
(2 rows)
MyTest=> SELECT * FROM testtable WHERE a;
a | b
---+---------
t | sic est
(1 row)
MyTest=> SELECT * FROM testtable WHERE a = true;
a | b
---+---------
t | sic est
(1 row)
5.비트 문자열 유형:
비트 문자열 은 1 과 0 의 문자열 이다.그것들 은 저장 과 시각 화 비트 마스크 에 사용 할 수 있다.우 리 는 두 가지 유형의 SQL 비트 유형 이 있 습 니 다.bit(n)와 bit varying(n);이곳 의 n 은 정수 다.bit 형식의 데 이 터 는 길이 n 과 정확하게 일치 해 야 합 니 다.짧 거나 긴 데 이 터 를 저장 하려 는 것 은 잘못된 것 이다.형식 bit varying 데 이 터 는 가장 긴 n 의 길 어 지 는 유형 입 니 다.더 긴 꼬치 는 거부 당 합 니 다.길이 가 없 는 bit 를 쓰 는 것 은 bit(1)와 같 고 길이 가 없 는 bit varying 은 길이 제한 이 없 는 것 과 같다.
이 유형 에 대해 마지막 으로 알려 야 할 것 은 우리 가 한 비트 문자열 값 을 bit(n)로 명확 하 게 바 꾸 면 오른쪽 이 잘 리 거나 오른쪽 에서 0 을 고 쳐 서 n 자리 가 될 때 까지 오류 가 발생 하지 않 습 니 다.유사 하 게,만약 우리 가 명확 하 게 비트 문자열 수 치 를 bit varying(n)으로 변환 한다 면,만약 그것 이 n 위 를 초과 한다 면,그것 의 오른쪽 은 절 단 될 것 이다.다음 과 같은 구체 적 인 사용 방식 을 보십시오.
MyTest=> CREATE TABLE testtable (a bit(3), b bit varying(5));
CREATE TABLE
MyTest=> INSERT INTO testtable VALUES (B'101', B'00');
INSERT 0 1
MyTest=> INSERT INTO testtable VALUES (B'10', B'101');
ERROR: bit string length 2 does not match type bit(3)
MyTest=> INSERT INTO testtable VALUES (B'10'::bit(3), B'101');
INSERT 0 1
MyTest=> SELECT * FROM testtable;
a | b
-----+-----
101 | 00
100 | 101
(2 rows)
MyTest=> SELECT B'11'::bit(3);
bit
-----
110
(1 row)
1.배열 형식 설명:
1).필드 에 배열 형식 이 있 는 표를 만 듭 니 다.
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[] -- integer[4] integer ARRAY[4]
);
MyTest=# INSERT INTO sal_emp VALUES ('Bill', '{11000, 12000, 13000, 14000}');
INSERT 0 1
MyTest=# INSERT INTO sal_emp VALUES ('Carol', ARRAY[21000, 22000, 23000, 24000]);
INSERT 0 1
MyTest=# SELECT * FROM sal_emp;
name | pay_by_quarter
--------+---------------------------
Bill | {11000,12000,13000,14000}
Carol | {21000,22000,23000,24000}
(2 rows)
다른 언어 와 마찬가지 로 PostgreSQL 의 배열 도 아래 표 시 된 숫자(괄호 안에 쓰기)를 통 해 접근 합 니 다.다만 PostgreSQL 의 배열 요소 의 아래 표 시 는 1 부터 n 으로 끝 납 니 다.
MyTest=# SELECT pay_by_quarter[3] FROM sal_emp;
pay_by_quarter
----------------
13000
23000
(2 rows)
MyTest=# SELECT name FROM sal_emp WHERE pay_by_quarter[1] <> pay_by_quarter[2];
name
------
Bill
Carol
(2 rows)
MyTest=# SELECT name,pay_by_quarter[1:3] FROM sal_emp;
name | pay_by_quarter
--------+---------------------
Bill | {11000,12000,13000}
Carol | {21000,22000,23000}
(2 rows)
1).모든 배열 값 대신:
--UPDATE sal_emp SET pay_by_quarter = ARRAY[25000,25000,27000,27000] WHERE name = 'Carol'; 。
MyTest=# UPDATE sal_emp SET pay_by_quarter = '{31000,32000,33000,34000}' WHERE name = 'Carol';
UPDATE 1
MyTest=# SELECT * FROM sal_emp;
name | pay_by_quarter
--------+---------------------------
Bill | {11000,12000,13000,14000}
Carol | {31000,32000,33000,34000}
(2 rows)
MyTest=# UPDATE sal_emp SET pay_by_quarter[4] = 15000 WHERE name = 'Bill';
UPDATE 1
MyTest=# SELECT * FROM sal_emp;
name | pay_by_quarter
--------+---------------------------
Carol | {31000,32000,33000,34000}
Bill | {11000,12000,13000,15000}
(2 rows)
MyTest=# UPDATE sal_emp SET pay_by_quarter[1:2] = '{37000,37000}' WHERE name = 'Carol';
UPDATE 1
MyTest=# SELECT * FROM sal_emp;
name | pay_by_quarter
--------+---------------------------
Bill | {11000,12000,13000,15000}
Carol | {37000,37000,33000,34000}
(2 rows)
MyTest=# UPDATE sal_emp SET pay_by_quarter[5] = 45000 WHERE name = 'Bill';
UPDATE 1
MyTest=# SELECT * FROM sal_emp;
name | pay_by_quarter
--------+---------------------------------
Carol | {37000,37000,33000,34000}
Bill | {11000,12000,13000,15000,45000}
(2 rows)
1).가장 간단 하고 직접적인 방법:
SELECT * FROM sal_emp WHERE pay_by_quarter[1] = 10000 OR
pay_by_quarter[2] = 10000 OR
pay_by_quarter[3] = 10000 OR
pay_by_quarter[4] = 10000;
SELECT * FROM sal_emp WHERE 10000 = ANY (pay_by_quarter); -- 10000,where 。
SELECT * FROM sal_emp WHERE 10000 = ALL (pay_by_quarter); -- 10000 ,where 。
PostgreSQL 의 복합 유형 은 C 언어 와 유사 한 구조 체 이 고 Oracle 의 기록 유형 으로 볼 수 있 지만 복합 유형 이라는 이름 이 적당 하 다 고 생각 합 니 다.그것 은 사실상 필드 이름과 데이터 형식의 목록 일 뿐이다.PostgreSQL 은 간단 한 데이터 형식 처럼 복합 형식 을 사용 할 수 있 습 니 다.예 를 들 어 표 필드 는 복합 형식 으로 설명 할 수 있다.
1.성명 복합 유형:
다음은 두 가지 간단 한 성명 예시 입 니 다.
CREATE TYPE complex AS (
r double,
i double
);
CREATE TYPE inventory_item AS (
name text,
supplier_id integer,
price numeric
);
CREATE TABLE on_hand (
item inventory_item,
count integer
);
2.복합 유형 값 입력:
우 리 는 텍스트 상수 방식 으로 복합 형식 값 을 표시 할 수 있 습 니 다.즉,괄호 안에 필드 값 을 둘러싸 고 쉼표 로 구분 할 수 있 습 니 다.모든 필드 값 을 작은 따옴표 로 묶 을 수 있 습 니 다.만약 값 자체 에 쉼표 나 괄호 가 포함 되 어 있다 면,작은 따옴표 로 묶 습 니 다.위의 inventoryitem 복합 형식의 입력 은 다음 과 같 습 니 다.
'("fuzzy dice",42,1.99)'
'("fuzzy dice",42,)'
'("",42,)'
ROW('fuzzy dice', 42, 1.99)
ROW('', 42, NULL)
('fuzzy dice', 42, 1.99)
('', 42, NULL)
복합 형식 에 있 는 필드 를 방문 하 는 것 과 데이터 시트 에 있 는 필드 를 방문 하 는 것 은 형식적 으로 매우 비슷 합 니 다.다만 이들 을 구분 하기 위해 서 입 니 다.PostgreSQL 은 복합 형식 에 있 는 필드 를 방문 할 때 유형 부분 을 괄호 로 묶 어서 헷 갈 리 지 않도록 해 야 합 니 다.예 를 들 어:
SELECT (item).name FROM on_hand WHERE (item).price > 9.99;
SELECT (on_hand.item).name FROM on_hand WHERE (on_hand.item).price > 9.99;
다음 과 같은 몇 가지 예 시 를 보십시오.
-- , ROW 。
INSERT INTO on_hand(item) VALUES(ROW("fuzzy dice",42,1.99));
-- , ROW 。
UPDATE on_hand SET item = ROW("fuzzy dice",42,1.99) WHERE count = 0;
-- , SET ,
-- 。
UPDATE on_hand SET item.price = (item).price + 1 WHERE count = 0;
-- , 。
INSERT INTO on_hand (item.supplier_id, item.price) VALUES(100, 2.2);
이 내용에 흥미가 있습니까?
현재 기사가 여러분의 문제를 해결하지 못하는 경우 AI 엔진은 머신러닝 분석(스마트 모델이 방금 만들어져 부정확한 경우가 있을 수 있음)을 통해 가장 유사한 기사를 추천합니다:
Redmine 데이터베이스를 MySQL에서 PostgreSQL로 마이그레이션 (보충)Redmine 의 Database 를 MySQL 로 운용하고 있었습니다만, MySQL 5.6 이상이나 MariaDB 에는 , , 이러한 티켓이 수년 동안 방치된 상황을 감안하여, PostgreSQL로 마이그레이션하기...
텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
CC BY-SA 2.5, CC BY-SA 3.0 및 CC BY-SA 4.0에 따라 라이센스가 부여됩니다.
좋은 웹페이지 즐겨찾기
