ORM - 1. ORM, Django ORM
NestJS로 프로젝트를 진행하다보면 자연스럽게 ORM을 사용하게 된다. 지금 진행하는 프로젝트의 경우 MongoDB를 사용하기 때문에 Mongoose라는 ODM을 사용하고 있는데, 사실 둘은 Document에 mapping하냐, Relation에 mapping하냐의 차이다.
보통 프로젝트들에서 아무렇지도 않게 ORM이나 ODM을 쓰다가, 갑자기 얘네가 이렇게 하라는 데로만 해도 괜찮다고?라는 생각이 들었다.
그래서 오늘은 상대적으로 이들에 대해 좀 더 알아보고자 한다.
1. ORM이란?
-
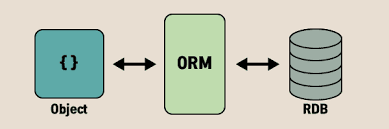
ORM(Object Relational Mapping)은 이름 그대로 Object와 Relation를 자동으로 매핑해주는 Framework이다. (ODM은 Object Document Mapping)
-
객체지향프로그래밍을 한다면, 우리는 필연적으로 class와 같은 object들을 만들게 되는데 DBMS를 통해서 DB에 넣기 위해서는 직접 SQL을 작성해야 한다.
-
ORM은 객체 간의 관계를 통해 자동으로 SQL문을 작성해준다.
ORM을 이용하면 SQL query 없이도 객체를 사용해서 DB의 데이터를 조작할 수 있게 된다.
장단점 자세히 보기..
-
Node.js에는 Sequelize가, Java에는 JPA/Hibernate가, Django에는 Django ORM이, Typescipt에는 Type ORM이 있다.
2. ORM 기초 지식
- ORM을 본격적으로 파해치기 전에 관련 기초 지식을 먼저 알아보자.
- DB에서 데이터를 가져오는 방식에는 Eager Loading과 Lazy Loading이 있다.
Eager Loading
- 참조해야할 데이터를 전부 미리 가져옴
- 연관된 리소스를 모두 한 번에 가져옴.
- 리소스의 일부만 사용한다면 낭비가 심함
- 초기 로딩 속도가 느리다.
Lazy Loading
- 참조해야할 데이터를 필요한 순간에 가져옴
- 초기 로딩 시간을 줄일 수 있음 (데이터를 필요할 때 호출하기 때문)
- 자원 소비를 좀 줄일 수 있음.
- Eager Loading에 비해서 query는 더 많이 발생한다.
-
모든 데이터를 항상 전부 가져오는 방식은 메모리 낭비가 심하기 때문에 ORM들은 Lazy Loading 방식으로 DB를 참조한다.
-
DB 참조 방식이 Lazy Loading이기 때문에 1+N query문제가 있다. (Eager-Loading 방식은 미리 쓸 데이터를 포함해 먼저 불러오기 때문에 이런 문제가 발생하지 않는다.)
-
1+N query가 아니더라도, ORM query자체가 high cost인 경우가 많아 ORM을 사용한다면, 이를 최적화하기 위해 신경을 많이 써야한다. (데이터가 적다면 상관 없겠지만..)
3. Django ORM
- 옛날에 자주 사용했던 Django의 ORM을 먼저 조사해봤다.
- Django의 manager class인 objects class의 method들을 통해서 statement를 작성한다.
- Django ORM은 해당 statement를 SQL로 변환한다.
- 해당 SQL queryset을 저장해뒀다가, 데이터가 사용되는 시점에 쿼리를 실행한다.
- ORM의 사용법은 다른 곳에서 알아보기로 하고, ORM에만 의존하면 생길 수 있는 문제에 대해서 조사해보자.
1. 1+N 쿼리 문제
ORM(Object Relational Mapping)은 이름 그대로 Object와 Relation를 자동으로 매핑해주는 Framework이다. (ODM은 Object Document Mapping)
객체지향프로그래밍을 한다면, 우리는 필연적으로 class와 같은 object들을 만들게 되는데 DBMS를 통해서 DB에 넣기 위해서는 직접 SQL을 작성해야 한다.
ORM은 객체 간의 관계를 통해 자동으로 SQL문을 작성해준다.
ORM을 이용하면 SQL query 없이도 객체를 사용해서 DB의 데이터를 조작할 수 있게 된다.
장단점 자세히 보기..
Node.js에는 Sequelize가, Java에는 JPA/Hibernate가, Django에는 Django ORM이, Typescipt에는 Type ORM이 있다.
- ORM을 본격적으로 파해치기 전에 관련 기초 지식을 먼저 알아보자.
- DB에서 데이터를 가져오는 방식에는 Eager Loading과 Lazy Loading이 있다.
Eager Loading
- 참조해야할 데이터를 전부 미리 가져옴
- 연관된 리소스를 모두 한 번에 가져옴.
- 리소스의 일부만 사용한다면 낭비가 심함
- 초기 로딩 속도가 느리다.
Lazy Loading
- 참조해야할 데이터를 필요한 순간에 가져옴
- 초기 로딩 시간을 줄일 수 있음 (데이터를 필요할 때 호출하기 때문)
- 자원 소비를 좀 줄일 수 있음.
- Eager Loading에 비해서 query는 더 많이 발생한다.
-
모든 데이터를 항상 전부 가져오는 방식은 메모리 낭비가 심하기 때문에 ORM들은 Lazy Loading 방식으로 DB를 참조한다.
-
DB 참조 방식이 Lazy Loading이기 때문에
1+N query문제가 있다. (Eager-Loading 방식은 미리 쓸 데이터를 포함해 먼저 불러오기 때문에 이런 문제가 발생하지 않는다.) -
1+N query가 아니더라도, ORM query자체가 high cost인 경우가 많아 ORM을 사용한다면, 이를 최적화하기 위해 신경을 많이 써야한다. (데이터가 적다면 상관 없겠지만..)
3. Django ORM
- 옛날에 자주 사용했던 Django의 ORM을 먼저 조사해봤다.
- Django의 manager class인 objects class의 method들을 통해서 statement를 작성한다.
- Django ORM은 해당 statement를 SQL로 변환한다.
- 해당 SQL queryset을 저장해뒀다가, 데이터가 사용되는 시점에 쿼리를 실행한다.
- ORM의 사용법은 다른 곳에서 알아보기로 하고, ORM에만 의존하면 생길 수 있는 문제에 대해서 조사해보자.
1. 1+N 쿼리 문제
- Django의 manager class인 objects class의 method들을 통해서 statement를 작성한다.
- Django ORM은 해당 statement를 SQL로 변환한다.
- 해당 SQL queryset을 저장해뒀다가, 데이터가 사용되는 시점에 쿼리를 실행한다.
앞서 말했듯, Eager Loading방식을 사용해서 데이터를 먼저 가져와야 해당 문제를 해결할 수 있다.
이를 해결하기 위해 select_related 메소드와 prefetch_related 메소드를 사용할 수 있다.
1) select_related
Select_related를 사용하면 Foreign key로 묶인 것들을 한 번에 가져온다.
User.objects.select_related('profile').filter(like__gte=100) 두 테이블간 join을 할 수 있는 구조에서 사용이 가능하며 쿼리는 1번만 실행된다. (join이 포함된 쿼리가 실행됨)
1번의 query로 가져온 정보를 사용하게 되기 때문에 Disk I/O가 줄어 더 효율적이게 되는 것!
select_related는 single object(one-to-one or many-to-one)이거나, 또는 정참조 foreign key 일 때 사용한다.
join을 통해 정보를 가져오기 때문에, 중간테이블을 이용해 관계를 형성하는 many-to-many 모델에서는 사용할 수 없다..
2) prefetch_related
관련된 테이블을 각각 모두 가져온 후, django 내에서 합친다.
User.objects.prefetch_related('profile', 'posts').filter(like__gte=100) select_releated를 사용할 수 없는 many-to-many 모델과 역참조 Foreign Key에서 주로 사용된다.
SQL의 join을 사용하지 않고, django 내에서 join을 실행한다.
2. Caching
같은 값을 가져오더라도, 값을 사용할 때 query를 사용하기 때문에(Lazy Loading), 값을 쓸 때마다 query가 실행된다.
예를 들면,
queryset = User.objects.all()
print(queryset[0])
print(queryset[0])
print(queryset[0])코드에서는 queryset을 print할 때 query를 실행한다. (또다시 Lazy-loading)
또한, 이렇게 가져온 데이터는 재사용하지 않고, 다음 print에서 또다시 query를 호출한다.
querylist = list(queryset)반면 이렇게 먼저 list로 저장하면 queryset의 결과를 caching하여 저장하기 때문에 이후에 querylist에 접근하더라도 추가적인 SQL호출은 없다.
즉, 불필요한 SQL호출을 줄일 수 있다.
5. ORM 자세한 장단점 설명
위에서 간단히 언급만 하고 넘어갔던 장단점들에 대해서, 왜 그런 장점과 단점이 생기는지를 추가적으로 조사해봤다.
장점
1. 완벽히 객체지향적인 코드를 작성할 수 있다.
- ORM을 사용하면, Query가 아닌 Method로 데이터를 조작할 수 있기 때문에, 개발자는 object model로 비즈니스 로직을 구현하는 데만 집중할 수 있다.
- 객체에 대한 코드를 별도로 작성하기에 코드 가독성이 올라간다.
- SQL은 절차적이고 순차적으로 접근하게 되는데, ORM을 사용하면 객체지향적 접근만 고려하면 된다.
2. 재사용 및 유지보수 편의성 증가
- ORM은 기존의 class같은 객체들과는 별개로 독립적으로 작성되며, 이들 또한 하나의 객체도 작성되기 때문에 재활용할 수 있다.
- 또한 매핑 정보가 명확하기에 ERD를 보는 것에 대한 의존도를 낮출 수 있다.
- ERD란 Entity Relationship Diagram인데, 시스템의 엔티티들에는 무엇이 있고, 각각의 관계는 어떤지 나타내는 다이어그램.
- SQL을 작성하기 위해선 해당 다이어그램을 통해 객체 간의 정보를 보고 작성해야 함.
- ORM에서는 매핑 정보가 명확하기 때문에 이를 볼 필요가 적어졌다는 뜻.
3. DBMS 종속성 하락
- 대부분의 ORM 솔루션은 DBMS에 종속적이지 않다.
- ORM에서 매핑 정보를 통해 DBMS에 query를 날리기 때문에, DBMS의 교체가 필요할 때도 적은 리스크로 이를 교체할 수 있다.
- 차바에선
equals,hashcode등의 오버라이드 기능을 통해서 가공할 수 있다고 한다.
단점
1. ORM만으로 완벽한 서비스를 구현하기 어려움.
- ORM을 사용하는 것은 매우 편리하지만, 그만큼 설계를 신중하게 해야함.
- 프로젝트가 복잡해질수록 설계 난이도가 올라가기 때문에 잘못된 설계로 인한 속도 저하 및 일관성 문제가 생길 수 있음.
- 자주 쓰는 대형 SQL 문의 경우에는 속도를 위한 별도의 튜닝이 필요할 수 있음.
2. Object-Relational Impendance Mismatch
- 아래와 같은 특성들에서 객체-관계 간 불일치가 발생한다.
1) 세분성 (Granulairy)
- DB에 있는 Table 수보다 더 많은 class를 갖는 모델이 생길 수 있다.
2) 상속성 (Inheritance)
- RDBMS에는 상속의 개념이 없기 때문에, 객체지향 언어의 특징인 상속이 제대로 구현될 수 없다.
3) 일관성 (Identity)
- RDBMS는 'sameness(동일성)'이라는 하나의 개념을 primary key를 사용해서 명확히 정의한다.
- 그러나 자바는 객체 식별 (
a==b)과 객체 동일성 (a.equals(b))을 모두 정의한다. - RDBMS는 PK가 같으면 동일한 record가 되지만, Java에서는 address가 같은 경우와 content가 같은 경우를 구분해서 정의한다는 뜻.
4) 연관성 (Associations)
- 객체지향 언어는 reference를 사용해 연관성을 나타내는 반면, RDBMS는 foreign key를 사용해서 연관성을 나타낸다.
- Java에서의 reference 참조는 방향성이 있지만, RDBMS에서는 FK로 인한 table-join에 방향성이 없다.
5) 탐색 (Navigation)
- 자바는 그래프형태로 하나의 연결에서 다른 연결로 이동하며 탐색한다.
- 이를 RDBMS에 적용할 경우 한 번 객체를 가져올 때마다 File I/O가 발생하기 때문에 비효율적인 방법이 된다.
- RDBMS에서는 SQL문을 최소화하고,
join을 통해 여러 엔티티를 한 번에 로드해서 원하는 엔티티를 선택하는 방식으로 탐색한다.
6. 1+N problem 추가 설명
Django ORM이 Lazy-Loading 방식이기 때문에 발생하는 문제점이다.
Lazy-Loading 방식은 ORM에서 명령을 실행할 때 가져오는게 아니라, 데이터를 불러와야하는 시점에 DB에 query를 실행하는 방식.
class User(models.Model):
username = models.CharField(max_length=32)
userId = models.CharField(max_length=32)
userPw = models.CharField(max_length=32)
like = models.IntegerField()
class Meta:
db_table = "user"
class UserProfile(models.Model):
name = models.CharField(max_length=32)
age = models.CharField(max_length=32)
class Meta:
db_table = "user_profile"다음과 같이 정의된 사용자 정보 model을 보자. 사용자의 간단한 정보들만 User 모델에 넣고, detail한 정보들은 UserProfile 모델에 넣었다. 이때 좋아요 수가 100이상인 사용자들의 실명 정보를 가져오는 method를 짜보자.
def get_popular_username():
result = []
users = User.objects.filter(like__gte=100)
for user in users:
name = user.profile.name
result.append(name)
return result이 경우 user.profile.name 부분에서 UserProfile 모델을 가져오기 위해서 새로운 쿼리를 발생하는데, for문을 돌 때마다 해당 쿼리를 실행하게 된다.
즉, 1 + N번 쿼리를 실행한다.
DBMS에서 쿼리를 실행해 데이터를 가져오는 것은 disk I/O를 발생시키기 때문에, 성능이 저하된다.
이를 1+N query문제라고 한다.
2편으로 이어집니다..
Author And Source
이 문제에 관하여(ORM - 1. ORM, Django ORM), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://velog.io/@cyw320712/ORM-1.-ORM-Django-ORM저자 귀속: 원작자 정보가 원작자 URL에 포함되어 있으며 저작권은 원작자 소유입니다.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
