K-means 클러스터링
13172 단어 파이썬scikit-learn
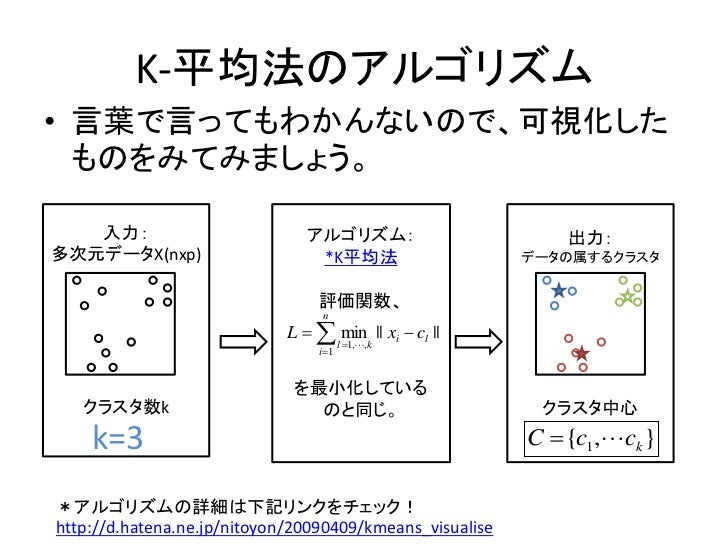
K-평균법 알고리즘
{kind=link}
우선은 샘플 데이터의 취득으로부터
# URL によるリソースへのアクセスを提供するライブラリをインポートする。
import urllib
# ウェブ上のリソースを指定する
url = 'https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/SchoolScore.txt'
# 指定したURLからリソースをダウンロードし、名前をつける。
urllib.urlretrieve(url, 'SchoolScore.txt')
('SchoolScore.txt', <httplib.HTTPMessage instance at 0x104143e18>)
import pandas as pd # データフレームワーク処理のライブラリをインポート
df = pd.read_csv("SchoolScore.txt", sep='\t', na_values=".") # データの読み込み
얻은 데이터를 확인합니다. 전체상도 바라볼 수 있습니다.
df.head() #データの確認
Student
일본어
Math
영어
0
0
80
85
100
1
1
96
100
100
2
2
54
83
98
3
3
80
98
98
4
4
90
92
91
df.iloc[:, 1:].head() #解析に使うデータは2列目以降
일본어
Math
영어
0
80
85
100
1
96
100
100
2
54
83
98
3
80
98
98
4
90
92
91
# 図やグラフを図示するためのライブラリをインポートする。
import matplotlib.pyplot as plt
%matplotlib inline
from pandas.tools import plotting # 高度なプロットを行うツールのインポート
plotting.scatter_matrix(df[df.columns[1:]], figsize=(6,6), alpha=0.8, diagonal='kde') #全体像を眺める
plt.show()

드디어 K-means 클러스터링의 실행입니다.
from sklearn.cluster import KMeans # K-means クラスタリングをおこなう
# この例では 3 つのグループに分割 (メルセンヌツイスターの乱数の種を 10 とする)
kmeans_model = KMeans(n_clusters=3, random_state=10).fit(df.iloc[:, 1:])
# 分類結果のラベルを取得する
labels = kmeans_model.labels_
# 分類結果を確認
labels
array([2, 2, 0, 2, 2, 1, 2, 2, 1, 2, 2, 2, 1, 2, 2, 0, 1, 2, 0, 0, 1, 0, 1,
1, 2, 2, 2, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1], dtype=int32)
이것으로 일종의 결과가 얻어졌습니다. 하지만, 이것만 보여도 핀과 오지 않으므로, 결과를 도시합시다.
분류 결과를 나타낸다.
# それぞれに与える色を決める。
color_codes = {0:'#00FF00', 1:'#FF0000', 2:'#0000FF'}
# サンプル毎に色を与える。
colors = [color_codes[x] for x in labels]
# 色分けした Scatter Matrix を描く。
plotting.scatter_matrix(df[df.columns[1:]], figsize=(6,6), color=colors, alpha=0.8, diagonal='kde') #データのプロット
plt.show()

일종의 색으로 구분되었습니다. 어쩐지 학력이 비슷한 클러스터로 나뉘어진 것 같은 생각이 듭니다만, 아직도 아직 핀과 오지 않을지도 모릅니다.
주성분 분석을 하여 K-means의 결과를 매핑한다.
#import sklearn #機械学習のライブラリ
from sklearn.decomposition import PCA #主成分分析器
#主成分分析の実行
pca = PCA()
pca.fit(df.iloc[:, 1:])
PCA(copy=True, n_components=None, whiten=False)
# データを主成分空間に写像 = 次元圧縮
feature = pca.transform(df.iloc[:, 1:])
# 第一主成分と第二主成分でプロットする
plt.figure(figsize=(6, 6))
for x, y, name in zip(feature[:, 0], feature[:, 1], df.iloc[:, 0]):
plt.text(x, y, name, alpha=0.8, size=10)
plt.scatter(feature[:, 0], feature[:, 1], alpha=0.8, color=colors)
plt.title("Principal Component Analysis")
plt.xlabel("The first principal component score")
plt.ylabel("The second principal component score")
plt.show()

K-means에서 어떻게 나뉘었는지, 이것으로 (아까보다는) 분명히 알았을지도 모릅니다.
도전
새 노트를 열고 다음 문제를 해결하십시오.
과제 1 : 아래 링크의 데이터를 이용하여 150 개의 얼룩을 K-means 법으로 3 개의 클러스터로 분류하십시오.
htps : // 등 w. Giteubuse r 콘텐트 t. 코 m/마 s 코 t1977/이 py 텐_의 데보오 k/마 s r/와 y다타/이리 s. txt
문제 2: 분류 결과를 Scatter Matrix에서 확인하십시오.
과제 3: 분류 결과를 주성분 분석으로 확인하십시오.
과제 4 : 클러스터 수를 4 개 또는 5 개 등으로 변경하면 어떻게되는지 확인하십시오.
Reference
이 문제에 관하여(K-means 클러스터링), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://qiita.com/maskot1977/items/34158d044711231c4292텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
