Python 정규 표현 식 을 기반 으로 검색 결과 의 사이트 주 소 를 추출 합 니 다.
그 중에서 해결 해 야 할 몇 가지 문제 와 관련된다.
1.검색 결과 텍스트 가 져 오기
더 많은 주 소 를 얻 기 위해 Google 의 고급 검색 기능 을 사 용 했 습 니 다.각 페이지 에 100 개의 결과 가 표 시 됩 니 다.
표 시 된 결 과 를 얻 으 면 원본 코드 를 볼 수 있 고 텍스트 파일 을 유지 하면 검색 결과 텍스트 가 있 습 니 다.
2.사이트 정 보 를 추출 하 는 방법 분석
먼저 가 져 온 페이지 를 분석 하고 사이트 정 보 를 어떤 방식 으로 추출 할 수 있 는 지 확인 해 야 합 니 다.
나 는 IE8 자체 개발 도구(F12 를 누 르 면 튀 어 나온다)의 탐색 기 기능 을 사용 하여 자신 이 관심 을 가 져 야 할 내용 이 어떤 특수 한 형식 이 있 는 지 살 펴 보 았 다.
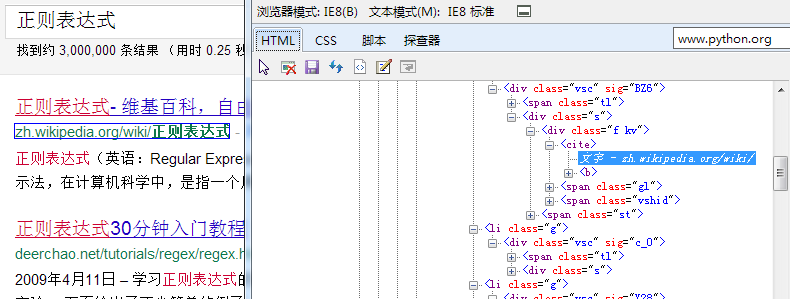
위의 그림 에서 볼 수 있 듯 이 내 가 필요 로 하 는 사이트 가 탭에 있 기 때문에 정규 표현 식 으로 이 텍스트 를 추출 하면 되 겠 습 니까?
3.정규 표현 식 을 작성 하여 사이트 주 소 를 가 져 옵 니 다.
다음은 표현 식 을 쓰 는 것 입 니 다.저 는 Python 3.2 로 작 성 했 습 니 다.사용 하기 편 합 니 다(~ ~)
코드 는 다음 과 같 습 니 다.먼저 검색 결과 페이지 를 e:/t3.txt 에 유지 하고 다음 코드 를 실행 합 니 다.
import re
p = re.compile(r'<cite>([^<>\/].+?)</cite>')
f = open("e:/t3.txt", encoding='utf-8')
content = f.read()
print ("
".join(p.findall(content)))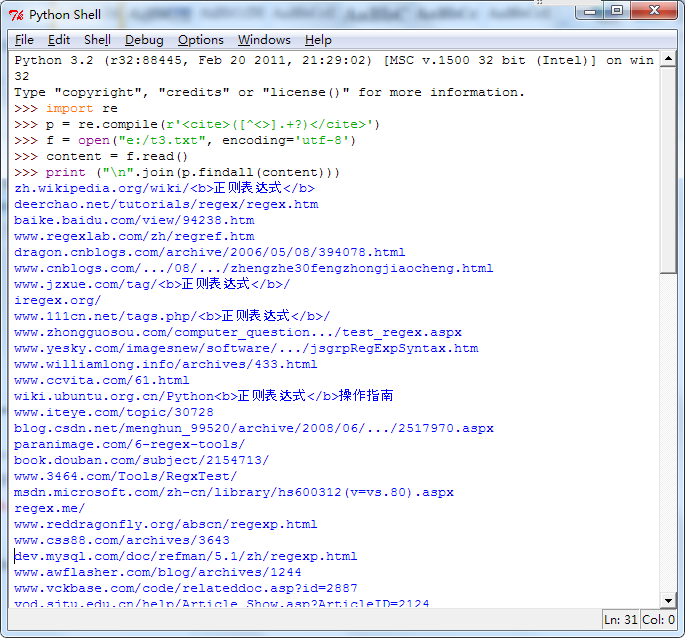
모든 사이트 주소 가 가 져 왔 는 지 실행 효과 도 를 대조 해 보 세 요.
이 내용에 흥미가 있습니까?
현재 기사가 여러분의 문제를 해결하지 못하는 경우 AI 엔진은 머신러닝 분석(스마트 모델이 방금 만들어져 부정확한 경우가 있을 수 있음)을 통해 가장 유사한 기사를 추천합니다:
Python의 None과 NULL의 차이점 상세 정보그래서 대상 = 속성 + 방법 (사실 방법도 하나의 속성, 데이터 속성과 구별되는 호출 가능한 속성 같은 속성과 방법을 가진 대상을 클래스, 즉 Classl로 분류할 수 있다.클래스는 하나의 청사진과 같아서 하나의 ...
텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
CC BY-SA 2.5, CC BY-SA 3.0 및 CC BY-SA 4.0에 따라 라이센스가 부여됩니다.
좋은 웹페이지 즐겨찾기
