상관 관계 - JMeter의 어려운 방법
5517 단어 javaperformancetestingtutorial
상관관계란 무엇입니까?
JMeter 생태계에는
correlation라는 공식 용어가 없습니다. 성능 엔지니어/테스터가 사용하는 일반적인 용어입니다. 또한 이 블로그 게시물에 correlation 단어로 제목을 지정하면 SEO에 도움이 됩니다 :)상관 관계는 응답 본문, 응답 헤더 또는 기본적으로 응답에서 문자열을 추출하는 프로세스입니다. 응답을 추출한 후 나중에 사용할 수 있도록 변수에 저장할 수 있습니다.
일반적인 예는 로그인 세션입니다. 세션 ID는 고유하고 횡설수설합니다. 스크립트에 하드 코딩하는 것은 효과적인 처리 방법이 아닙니다. 웹 서버 측 속성에 따라 만료될 수 있기 때문입니다.
상관 관계 - JMeter의 어려운 방법
JMeter에 추가하여 Groovy 스크립팅을 사용하여 응답에서
title 태그를 추출하는 것으로 시작하겠습니다. 아래는 테스트 계획 트리입니다.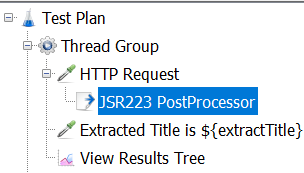 상관 관계 - JMeter의 어려운 방법
상관 관계 - JMeter의 어려운 방법다음은 Groovy 스크립트입니다.
response = prev.getResponseDataAsString() //Extract the previous response
def extractTitle = /<title>(.+?)<\/title>/
def matcher = response =~ extractTitle
if (matcher.size() >=1) {
println matcher.findAll()[0][1]
vars.put("extractTitle",matcher.findAll()[0][1])
}URL은 다음과 같습니다. https://jpetstore-qainsights.cloud.okteto.net/jpetstore/actions/Catalog.action
첫 번째 단계는
prev.getResponseDataAsString()를 사용하여 HTTP 응답을 문자열로 읽는 것입니다.prev는 previous SampleResult을 추출하는 API 호출입니다. 메서드getResponseDataAsString()를 사용하여 전체 응답을 문자열로 추출하여 변수에 저장할 수 있습니다.다음 두 줄은 정규식 패턴과 일치 조건을 정의합니다. Groovy에는 강력한 정규식 패턴 일치가 제공됩니다.
def extractTitle = /<title>(.+?)<\/title>/
def matcher = response =~ extractTitle다음 블록은 일치 항목이 >=1인지 확인한 다음 배열 목록에서 추출된 문자열을 인쇄합니다. 그런 다음
extractTitle 메서드를 사용하여 값을 변수vars.put에 저장합니다.if (matcher.size() >=1) {
println matcher.findAll()[0][1]
vars.put("extractTitle",matcher.findAll()[0][1])
}결과는 다음과 같습니다.
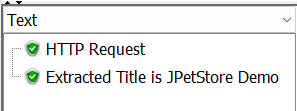 JMeter 출력
JMeter 출력위의 방법은 몇 가지 이유로 효과적이지 않습니다. 첫째, 원하는 문자열을 캡처하기 위한 배열 인덱스는 복잡한 응답에 대해 번거로울 수 있습니다. 둘째, 일반적으로 여기에서 사용하는 패턴은 HTML 응답이 아닌 텍스트 응답에 적합합니다. 복잡한 HTML 응답의 경우 정규식을 사용하면 성능이 향상되지 않을 수 있습니다.
GitHub Repo
JSoup 사용
HTML 응답을 효과적으로 처리하려면 JSoup과 같은 HTML 파서를 사용하는 것이 좋습니다.
JSoup은 실제 HTML 작업을 위한 Java 라이브러리입니다. 최고의 HTML5 DOM 메서드와 CSS 선택기를 사용하여 URL을 가져오고 데이터를 추출 및 조작하기 위한 매우 편리한 API를 제공합니다.
Grab 를 사용하면 JMeter가 종속 항목을 자체적으로 다운로드합니다. 그렇지 않으면 JSoup jar를 다운로드하여 lib 또는 ext 폴더에 보관해야 합니다.import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
import org.jsoup.select.Elements
@Grab(group='org.jsoup', module='jsoup', version='1.15.2')
response = prev.getResponseDataAsString() // Extract response
Document doc = Jsoup.parse(response)
println doc.title()doc 개체가 응답을 구문 분석하고 제목을 JMeter의 명령 프롬프트에 인쇄합니다.모든 링크와 해당 텍스트를 인쇄하려면 아래 코드 스니펫이 유용합니다.
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
import org.jsoup.select.Elements
@Grab(group='org.jsoup', module='jsoup', version='1.15.2')
response = prev.getResponseDataAsString() // Extract response
Document doc = Jsoup.parse(response)
println doc.title()
// To print all the links and its text
Elements links = doc.body().getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
println linkHref + linkText
}URL(http://computer-database.gatling.io/computers/new)에 대한 모든 목록 상자 요소와 임의 목록 상자 값을 인쇄하려면 아래 코드 스니펫을 사용하십시오.
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
import org.jsoup.select.Elements
@Grab(group='org.jsoup', module='jsoup', version='1.15.2')
response = prev.getResponseDataAsString() // Extract response
companyList = []
Random random = new Random()
Document doc = Jsoup.parse(response)
// To print all the list box elements
Elements lists = doc.body().select("select option")
for (Element list : lists) {
println "Company is " + list.text()
companyList.add(list.text())
}
// To print random list box element
println("The total companies are " + companyList.size())
println(companyList[random.nextInt(companyList.size())])마지막 말
배운 것처럼
prev API를 활용하여 응답을 추출한 다음 JSoup 라이브러리를 사용하거나 정규식 추출기 또는 JSON 추출기 등과 같은 기본 제공 요소를 사용하지 않고 어려운 방식으로 원하는 정규식을 작성하여 구문 분석할 수 있습니다. . 이 접근 방식은 시간을 절약하지 못할 수도 있지만 인터뷰와 같은 상황에서 유용한 이 접근 방식을 배우는 것은 가치가 있습니다.
Reference
이 문제에 관하여(상관 관계 - JMeter의 어려운 방법), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://dev.to/qainsights/correlation-the-hard-way-in-jmeter-m5i텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
