Apache Cassandra - 멋진 파트 2 - 데이터 모델링
기본적으로 넓은 열 저장소를 이해하기 전에 먼저 카산드라가 데이터를 저장하는 방식을 살펴봐야 합니다.
따라서 RDBMS 배경에서 오는 경우입니다. 그런 다음 말을 잡고 그것에 관한 모든 것을 잊어달라고 요청합니다.
Cassandra의 데이터 모델링을 이해하는 상향식 접근 방식을 살펴보겠습니다.
따라서 사용자 정보와 같은 정보를 저장해야 하는 경우 데이터를 저장해야 하는 문자열 배열을 갖게 됩니다.
예.
String[] information = new String[3];
["Gaurav","25","Post Graduation"]
그러나 보시다시피 이러한 방식으로 정보를 저장하는 것은 낭비입니다. 처음부터 정보[0]가 무엇을 나타내는지 등에 대한 기록을 유지해야 합니다.
다음에 동일한 접근 방식으로 데이터를 삽입해야 합니다.
여기 MAPS라는 구원자가 온다.
따라서 각 값에 이름을 할당한 다음 이름별로 값을 가져오므로 이제 순서는 그다지 중요하지 않습니다. 방법을 알아볼까요?
위의 예와 동일하게 진행하십시오.
Map<String, String> information = new HashMap<>();
information.put("name","gaurav");
information.put("age","25");
information.put("education","Post graduation");
NAME AGE Education
| | |
gaurav 25 PG
이제 어떻게 생각하세요?
괜찮아 보이는데?
이제 사용자의 다른 정보를 저장해야 한다고 가정해 봅시다.
이름/값 쌍의 일부 컬렉션을 통합할 방법이 없음을 의미합니다.
동일한 열 이름을 반복할 방법이 없습니다.
왜냐면 다시 하면
information.put("names","joshua");그러면 이전 이름이 손실됩니다.
따라서 열의 일부를 그룹화할 무언가가 필요합니다.
명확하게 주소를 지정할 수 있는 그룹에서 값을 함께 표시합니다.
이 열 그룹을 참조하려면 키가 필요합니다.
행이 필요합니다.
그런 다음 단일 행을 얻으면 전체 열 패밀리를 얻을 수 있습니다.
그래서 지금 우리에게 필요한 것은 이런 것입니다.
Map<Row(Primary Key), ColumnarClass> cassandraDataModelling = new HashMap<>();
class ColumnarClass<T>{
Dynamic column names;
TimeStamp; (necessary field)
}
이제 위 데이터 구조의 이미지는 다음과 같습니다.
Image Link
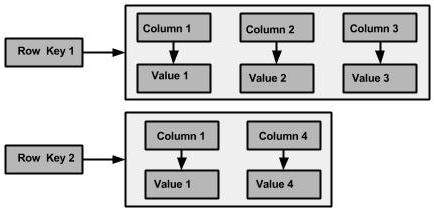{kind=link}
Cassandra는 컬럼 패밀리를 유사한 데이터를 연결하는 논리적 분할로 정의합니다.
예를 들어 사용자 컬럼 패밀리, 호텔 컬럼 패밀리,
주소록 컬럼 패밀리 등. 이런 식으로 column family는 다소
관계형 세계의 테이블과 유사합니다.
더 쉽고 시각적으로 매력적으로 보이도록.
User: ColumnFamily 1
Josh: RowKey
email: [email protected], ColumnName:Value
age: 22 ColumnName:Value
Gaurav: RowKey
email: gaurav@mailcom ColumnName:Value
Vehicle: ColumnFamily 2
Bike: RowKey
Period: 1968-2010 ColumnName:Value
유사하게 당신은 지도 즉,
Map<RowKey, Map<RowKey, ColumnarClass>> = new HashMap<>();Image Link
{kind=link}
컬럼 패밀리의 행이 이름/값 쌍의 콜렉션을 보유하는 경우 수퍼
열 패밀리에는 하위 열이 있으며 여기서 하위 열은 이름이 지정된 열 그룹입니다.
따라서 일반 열 패밀리의 값 주소는 열을 가리키는 행 키입니다.
값을 가리키는 이름, 유형의 열 패밀리에 있는 값의 주소
"super"는 하위 열 이름을 가리키는 열 이름을 가리키는 행 키입니다.
값을 가리킵니다. 약간 다르게 표현하면 슈퍼 컬럼 패밀리의 행은 여전히 다음을 포함합니다.
각 열에는 하위 열이 포함됩니다.
(이 텍스트 소스는 Cassandra The definitive 가이드에서 가져왔습니다.)
이것이 Cassandra의 데이터 모델을 보는 상향식 접근 방식입니다.
이것에 더 많은 것이 있습니다. 그러나 다시 한 번 말을 잡고 다음 Awesome Cassandra 기사를 계속 지켜봐 주시기 바랍니다.
제안 사항이나 잘못되었다고 생각되는 사항이 있는 경우. 자유롭게 의견을 남겨주세요.
고맙습니다
Reference
이 문제에 관하여(Apache Cassandra - 멋진 파트 2 - 데이터 모델링), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://dev.to/gauravguptadeveloper/apache-cassandra-awesome-part-2-data-modelling-138b텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
