Amundsen, 데이터 카탈로그 엔진 사용
5466 단어 Python
데이터 카탈로그를 검색·발견할 수 있는 OSS'아름undsen'을 사용했기 때문에 소개하려고 합니다.
이른바 데이터 디렉터리
데이터 디렉터리는 광범위한 의미를 가지고 있지만 이번에는 이른바 상업 데이터 디렉터리로 사용된다.간단하게 말하면 상업적 이용을 목적으로 하는 기업 내에 저장된 데이터 사전과 같다.테이블 정의와 열 정의의 설명 등.
이른바 Amundsen
Amundsen is a data discovery and metadata engine for improving the productivity of data analysts, data scientists and engineers when interacting with data.
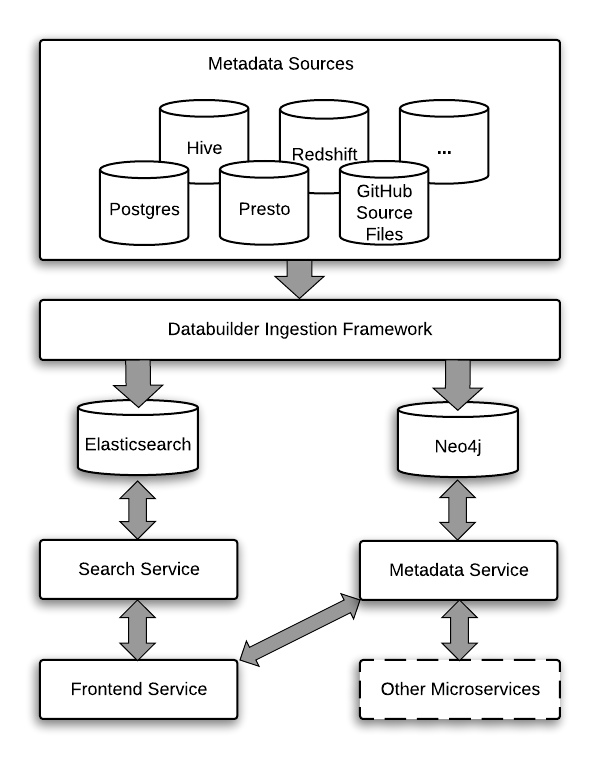
Amundsen은 데이터 분석가, 데이터 과학 및 엔지니어의 생산성을 향상시키는 데이터를 검색할 수 있는 메타데이터 엔진입니다.Amundsen은 다음 그림처럼 마이크로 서비스화되었다.

메타데이터(Sources 등)에서 메타데이터(표 및 패턴 정보)를 가져와 Neo4j와 Elasticsearch에 넣습니다.이 정보에 따르면 Amudsen의 검색엔진 UI(Fronted Service)에서 정보를 확인할 수 있다.
현지에 Amundsen 구축
docker를 준비했기 때문에 로컬에서 간단하게 일어설 수 있습니다.
amundsen의github설치 방법에 자세하게 썼어요. 거기서 확인해 주세요.$ git clone --recursive [email protected]:amundsen-io/amundsen.git
$ cd (cloneしたamundsenのディレクトリ)
$ docker-compose -f docker-amundsen.yml up
Amundsen에서 추출된 데이터
데이터 패턴 정보를 얻어 Amundsen에 반영하는 Frammework(amundsenbuilder)를 준비했기 때문에 이를 이용해 데이터베이스에서 데이터를 쉽게 얻을 수 있다.
builder에 필요한 패키지를 설치합니다.$ cd (amundsenbuilderのディレクトリ)
$ python3 -m venv venv
$ source venv/bin/activate
$ pip3 install -r requirements.txt
$ python3 setup.py install
example 스크립트를 준비했기 때문에 이것을 실행합니다.
sample_data_loader에서 샘플의 csv 파일에서amundsen에 데이터를 불러옵니다.$ python3 example/scripts/sample_data_loader.py
gle에서 디렉토리를 가져오는 스크립트(sample glue loader.py)도 있습니다.아무것도 바꾸지 않고 실행하면 glue에서 모든 것을 꺼냅니다. 그래서 Filter로 gl data catallog의 Name을 Filter로 변경합니다.
https://github.com/amundsen-io/amundsendatabuilder/blob/master/example/scripts/sample_glue_loader.py#L33 def create_glue_extractor_job(filter_key: []):
# ~~省略~~
'extractor.glue.{}'.format(GlueExtractor.FILTER_KEY): filter_key,
# ~~省略~~
if __name__ == "__main__":
filter = [{
'Key': 'Name',
'Value': 'accounts',
}] # glueのaccountsでfilter
glue_job = create_glue_extractor_job(filter)
glue_job.launch()
es_job = create_es_publisher_job()
es_job.launch()
Filter 형식으로 키,Value의 dictkey의object 목록을 건네줍니다.보토 3search_tables을 사용하기 때문에 키와 밸류는 필수다.
실행할 때credential(aws access key id,aws secret access key,token 등)을 미리 발행해야 aws의gulue에 접근할 수 있습니다.$ python3 example/scripts/sample_glue_loader.py
처리가 끝난 후localhost:5000에서amundsen에 접근하여 데이터 디렉터리가 있는지 확인합니다.
(아래 그림은 실제 얻은 데이터가 아니라 Amundsen의 github 그림입니다.)

사용할 수 있는 곳
Amundsen is a data discovery and metadata engine for improving the productivity of data analysts, data scientists and engineers when interacting with data.
Amundsen은 데이터 분석가, 데이터 과학 및 엔지니어의 생산성을 향상시키는 데이터를 검색할 수 있는 메타데이터 엔진입니다.Amundsen은 다음 그림처럼 마이크로 서비스화되었다.
{kind=link}
메타데이터(Sources 등)에서 메타데이터(표 및 패턴 정보)를 가져와 Neo4j와 Elasticsearch에 넣습니다.이 정보에 따르면 Amudsen의 검색엔진 UI(Fronted Service)에서 정보를 확인할 수 있다.
현지에 Amundsen 구축
docker를 준비했기 때문에 로컬에서 간단하게 일어설 수 있습니다.
amundsen의github설치 방법에 자세하게 썼어요. 거기서 확인해 주세요.$ git clone --recursive [email protected]:amundsen-io/amundsen.git
$ cd (cloneしたamundsenのディレクトリ)
$ docker-compose -f docker-amundsen.yml up
Amundsen에서 추출된 데이터
데이터 패턴 정보를 얻어 Amundsen에 반영하는 Frammework(amundsenbuilder)를 준비했기 때문에 이를 이용해 데이터베이스에서 데이터를 쉽게 얻을 수 있다.
builder에 필요한 패키지를 설치합니다.$ cd (amundsenbuilderのディレクトリ)
$ python3 -m venv venv
$ source venv/bin/activate
$ pip3 install -r requirements.txt
$ python3 setup.py install
example 스크립트를 준비했기 때문에 이것을 실행합니다.
sample_data_loader에서 샘플의 csv 파일에서amundsen에 데이터를 불러옵니다.$ python3 example/scripts/sample_data_loader.py
gle에서 디렉토리를 가져오는 스크립트(sample glue loader.py)도 있습니다.아무것도 바꾸지 않고 실행하면 glue에서 모든 것을 꺼냅니다. 그래서 Filter로 gl data catallog의 Name을 Filter로 변경합니다.
https://github.com/amundsen-io/amundsendatabuilder/blob/master/example/scripts/sample_glue_loader.py#L33 def create_glue_extractor_job(filter_key: []):
# ~~省略~~
'extractor.glue.{}'.format(GlueExtractor.FILTER_KEY): filter_key,
# ~~省略~~
if __name__ == "__main__":
filter = [{
'Key': 'Name',
'Value': 'accounts',
}] # glueのaccountsでfilter
glue_job = create_glue_extractor_job(filter)
glue_job.launch()
es_job = create_es_publisher_job()
es_job.launch()
Filter 형식으로 키,Value의 dictkey의object 목록을 건네줍니다.보토 3search_tables을 사용하기 때문에 키와 밸류는 필수다.
실행할 때credential(aws access key id,aws secret access key,token 등)을 미리 발행해야 aws의gulue에 접근할 수 있습니다.$ python3 example/scripts/sample_glue_loader.py
처리가 끝난 후localhost:5000에서amundsen에 접근하여 데이터 디렉터리가 있는지 확인합니다.
(아래 그림은 실제 얻은 데이터가 아니라 Amundsen의 github 그림입니다.)
사용할 수 있는 곳
$ git clone --recursive [email protected]:amundsen-io/amundsen.git
$ cd (cloneしたamundsenのディレクトリ)
$ docker-compose -f docker-amundsen.yml up
데이터 패턴 정보를 얻어 Amundsen에 반영하는 Frammework(amundsenbuilder)를 준비했기 때문에 이를 이용해 데이터베이스에서 데이터를 쉽게 얻을 수 있다.
builder에 필요한 패키지를 설치합니다.
$ cd (amundsenbuilderのディレクトリ)
$ python3 -m venv venv
$ source venv/bin/activate
$ pip3 install -r requirements.txt
$ python3 setup.py install
sample_data_loader에서 샘플의 csv 파일에서amundsen에 데이터를 불러옵니다.
$ python3 example/scripts/sample_data_loader.py
https://github.com/amundsen-io/amundsendatabuilder/blob/master/example/scripts/sample_glue_loader.py#L33
def create_glue_extractor_job(filter_key: []):
# ~~省略~~
'extractor.glue.{}'.format(GlueExtractor.FILTER_KEY): filter_key,
# ~~省略~~
if __name__ == "__main__":
filter = [{
'Key': 'Name',
'Value': 'accounts',
}] # glueのaccountsでfilter
glue_job = create_glue_extractor_job(filter)
glue_job.launch()
es_job = create_es_publisher_job()
es_job.launch()
실행할 때credential(aws access key id,aws secret access key,token 등)을 미리 발행해야 aws의gulue에 접근할 수 있습니다.
$ python3 example/scripts/sample_glue_loader.py
(아래 그림은 실제 얻은 데이터가 아니라 Amundsen의 github 그림입니다.)
사용할 수 있는 곳
아쉬운 점/ 앞으로의 기대
Amundsen에 대해 설명했습니다.
Reference
이 문제에 관하여(Amundsen, 데이터 카탈로그 엔진 사용), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://qiita.com/asaki15/items/b243d19eb78d34752cfd텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
