배치 및 스트리밍 시스템의 노하우
또 여기서 배치 처리는 해당 시간대에 발생한 모든 데이터를 대상으로 처리하는 1시간 1회 또는 1일 1회를 말한다.또한 흐름 처리는 발생하는 모든 데이터를 순서대로 처리하는 흐름 처리를 말한다.또 이번에는 데이터의 합계 처리 시스템을 주로 구상했다.
스트리밍이란 배치 처리의 실행 간격을 최소화하는 거죠?그렇게 말하는 사람도 많다.그러니까 모든 데이터는 일괄 처리를 거치면 된다는 거야.만약 처리된 원가가 0의 이상적인 세계라면 그것은 옳다.그러나 현실 세계에서 이'원가'가 매우 크기 때문에 일괄 처리와 유동 처리는 완전히 다른 체계 구조를 사용한다.
여기에는 처리의 논리가 아니라 운용에 있어서 일괄 처리와 흐름 처리의'신경 쓰는 점'의 차이를 고려해 보자.
일괄 처리 시 시간 소요

파이프라인 관리
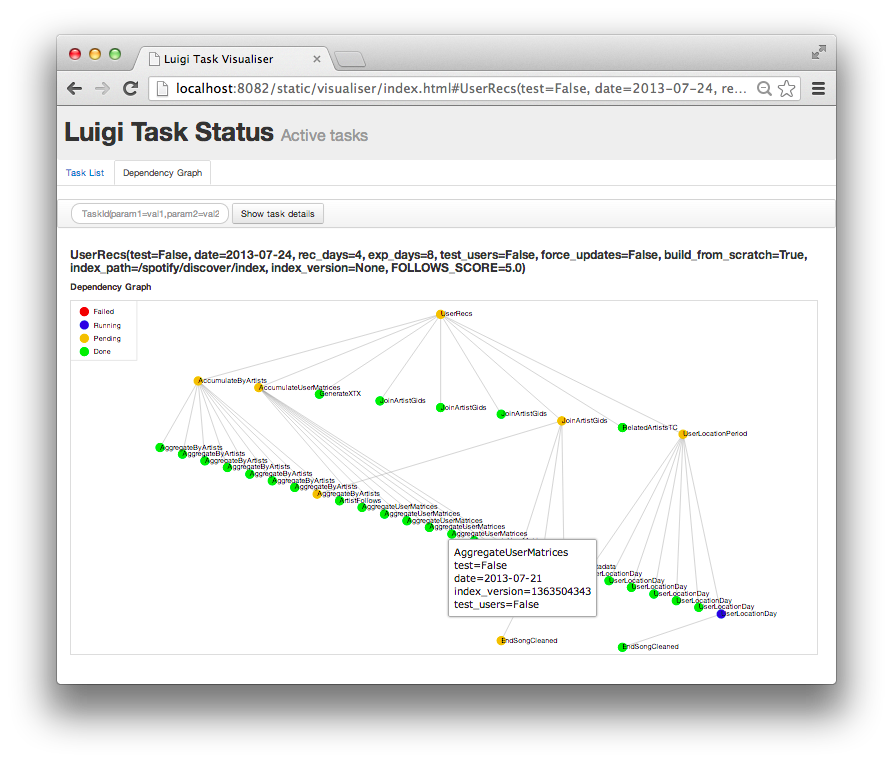
일괄 처리는 많은 데이터를 총괄 처리하기 때문에 한 번의 집행 시간이 길어지기 쉽다.여러 개의 일괄 처리에서 파이프라인을 조립하는 상황에서 하나의 처리의 집행 지연도 다른 일괄 처리에 파급될 수 있다.따라서 이러한 영향을 최대한 빨리 파악하기 위해 우리는 일괄 처리의 집행 시간 경보를 꼼꼼히 설계하고 작업의 집행 상황을 가시화할 것이다.이에 따라 파이프라인 관리를 위한 OSS 프레임도 등장했다.

https://raw.githubusercontent.com/spotify/luigi/master/doc/user_recs.png
{kind=link}
정상적인 상황에서도 입력 데이터가 스매시된 경우(할인 같은 것을 한 경우) 집행시간이 갑자기 늘어난다.이 경우'정상적으로 작동하지만 시간이 오래 걸린다'거나'중도에 실패했지만 오류가 끝나지 않았다'거나 구분할 수 없다.또 언제 끝날지 예측할 수 없기 때문에 파이프의 영향은 예측할 수 없을 것이다.따라서 어느 정도 집행되는지 감시하는 것이 중요하다.내 경우 1000건당 1회 정도의 주파수로 진도를 표시하는 로그 (모든 ○건/현재 ○건을 처리하고 싶은 형식) 를 출력한다.
print "$line_count / $line_total" if $line % 1000 == 0;
미리 예측하다
일괄 처리의 경우 대부분 입력 데이터량을 사전에 알고 있다.따라서 실행하기 전에 어느 정도의 성능 계획을 세울 수 있다.시간마다 필요한 처리량을 알고 있기 때문에 필요한 실례수를 계산할 수 있다.당신은 먼저 충분한 시스템 자원을 준비한 후에 처리를 시작할 수 있습니다.
흐름 처리 대기 불가

유량 제어
흐름 처리 시 입력 데이터량의 스매시 변화폭이 현저히 커진다.스파이크할 때 데이터 양도 감당하는 시스템이 됐으면 좋겠지만, 현실적으로 스파이크할 때도 감당하는 시스템은 통상 초과 규격으로 바뀌어 원가가 늘어난다.따라서 시스템 내에서 흐르는 데이터의 양을 균등화하는 방법이 대부분이다.
예를 들어, 스트리밍된 파이프라인 사이에 작업 대기열을 삽입하면 트래픽이 증가하더라도 입력 데이터를 작업 대기열에 임시로 저장하여 스트리밍 자체의 데이터 처리량을 대체적으로 일정하게 유지할 수 있습니다.
로그 오류 후
재집행에 시간이 걸리지 않기 때문에 로그'오류가 발생하면 들어간다'를 집행하는 방법도 현실적이다.특히 흐름 처리의 경우 1처리의 실행 시간이 매우 짧기 때문에 실행 로그를 너무 많이 출력하면 처리 성능에 큰 영향을 미칠 수 있다.따라서 개발할 때 운용에 사용할 집행일지를 설계하지 않고 운용 중 오류가 발생한 부분을 중심으로 집행일지를 늘리는 것이 타당하다.
if (IS_DEBUG) {
console.log("user_id = " + user_id);
}
동적 기획
흐름 처리는 항상 지속적으로 이동하기 때문에 처리를 시작할 때 장래의 성능을 예측하기 어렵다.따라서 예측할 수 있는 일보다 동적 시스템 확장을 우선적으로 고려해야 한다.
총결산
실제로 KARTE는 배치 및 스트리밍을 함께 사용합니다.여러 가지 통계 시스템을 조합해서 가장 적합한 것을 만들고 싶은 사람은 반드시 프라이드에 가야 한다!
Reference
이 문제에 관하여(배치 및 스트리밍 시스템의 노하우), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://qiita.com/mkataigi/items/45d46185526f9bda9ce0텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
