Apache Spark 1.6 Dataset API를 신속하게 사용해보십시오.
2015/12/14 현재 아직 릴리스되지 않았지만, 연내 중에는 릴리스될 것.
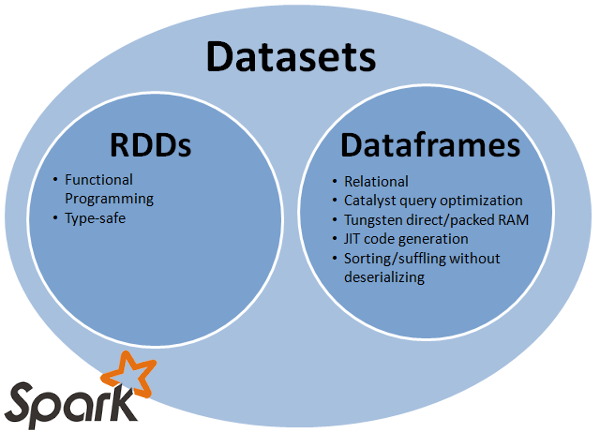
배경
RDD는 Low Level API로 유연하지만 최적화가 어렵습니다.
Dataset API 등장

이미지는 h tp : // / ch 또는 td t. bgs포 t. jp
{kind=link}
Dataset API의 요구사항 정의는 SPARK-9999에 상세히 쓰여진 대로 크게 아래의 4가지가 됩니다.
Fast
Typesafe
Java Compatible
Interoperates with DataFrames
Let's give it a try
Spark 1.6.0 다운로드
해동 후 /usr/local/spark-1.6.0 에 복사
Spark 소스에 동봉된 파일을 사용하여 비교해 보기
/usr/local/spark-1.6.0/bin/spark-shell 起動// 各自のパスを合わせて設定
scala> val peopleFile = "/usr/local/spark-1.6.0/examples/src/main/resources/people.json"
// JSON → DataFrame
scala> val df = sqlContext.read.json(peopleFile)
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
// 中身確認
scala> df.printSchema
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
scala> df.show
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
// Datasetを使うため、case class 定義
scala> case class Person(age: Long, name: String)
// DataFrameからDatasetに変換
scala> val ds = df.as[Person]
ds: org.apache.spark.sql.Dataset[Person] = [age: bigint, name: string]
// DataFrameでの20歳以上の人を取得
// DataFrameは行列計算に特化したフレームワークなので、カラム名を指定する必要がある
scala> df.where($"age" >= 20).show
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
// Datasetでの20歳以上の人を取得
// DatasetはDataFrameのRowをJVMオブジェクト(この例ではPerson)として扱えるため、UDFが適用が簡単
scala> ds.filter(_.age >= 20).show
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
// Dataset → DataFrame
scala> val df2 = ds.toDF
df2: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
// Dataset → RDD
scala> val rdd = ds.rdd
rdd: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[121] at rdd at <console>:33
// 少し複雑な処理(年代別人数集計)
scala> import org.apache.spark.sql.types._
// DataFrameの場合
scala> :paste
df.where($"age" > 0)
.groupBy((($"age" / 10) cast IntegerType) * 10 as "decade")
.agg(count($"name"))
.orderBy($"decade")
.show
+------+-----------+
|decade|count(name)|
+------+-----------+
| 10| 1|
| 30| 1|
+------+-----------+
// Datasetの場合
scala> :paste
ds.filter(_.age > 0)
.groupBy(p => (p.age / 10) * 10)
.agg(count("name"))
// orderByがないようなので、DFへ変換(これはやや不便)
.toDF().withColumnRenamed("value", "decade").orderBy("decade")
.show
+------+-----------+
|decade|count(name)|
+------+-----------+
| 10| 1|
| 30| 1|
+------+-----------+
다른 예는 databricks 사이트를 참조하십시오.
Dataset API 이외의 Spark1.6.0에 대해서는 이쪽
요약
// 各自のパスを合わせて設定
scala> val peopleFile = "/usr/local/spark-1.6.0/examples/src/main/resources/people.json"
// JSON → DataFrame
scala> val df = sqlContext.read.json(peopleFile)
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
// 中身確認
scala> df.printSchema
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
scala> df.show
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
// Datasetを使うため、case class 定義
scala> case class Person(age: Long, name: String)
// DataFrameからDatasetに変換
scala> val ds = df.as[Person]
ds: org.apache.spark.sql.Dataset[Person] = [age: bigint, name: string]
// DataFrameでの20歳以上の人を取得
// DataFrameは行列計算に特化したフレームワークなので、カラム名を指定する必要がある
scala> df.where($"age" >= 20).show
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
// Datasetでの20歳以上の人を取得
// DatasetはDataFrameのRowをJVMオブジェクト(この例ではPerson)として扱えるため、UDFが適用が簡単
scala> ds.filter(_.age >= 20).show
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
// Dataset → DataFrame
scala> val df2 = ds.toDF
df2: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
// Dataset → RDD
scala> val rdd = ds.rdd
rdd: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[121] at rdd at <console>:33
// 少し複雑な処理(年代別人数集計)
scala> import org.apache.spark.sql.types._
// DataFrameの場合
scala> :paste
df.where($"age" > 0)
.groupBy((($"age" / 10) cast IntegerType) * 10 as "decade")
.agg(count($"name"))
.orderBy($"decade")
.show
+------+-----------+
|decade|count(name)|
+------+-----------+
| 10| 1|
| 30| 1|
+------+-----------+
// Datasetの場合
scala> :paste
ds.filter(_.age > 0)
.groupBy(p => (p.age / 10) * 10)
.agg(count("name"))
// orderByがないようなので、DFへ変換(これはやや不便)
.toDF().withColumnRenamed("value", "decade").orderBy("decade")
.show
+------+-----------+
|decade|count(name)|
+------+-----------+
| 10| 1|
| 30| 1|
+------+-----------+
Reference
이 문제에 관하여(Apache Spark 1.6 Dataset API를 신속하게 사용해보십시오.), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://qiita.com/teru1000/items/d59df35b87d87e4824a9텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
