조던은 플로리다 주립 대학 서점에 있다
13209 단어 webscrapingaxiosluminatijavascript
나는 가끔 requests for web scraping targets on reddit를 낸다.오늘의 곤경은 바로 이 요구의 결과이다.한 사용자는 특정 대학 사이트에 열거된 서적과 가격, 기타 정보를 얻기를 원한다.
이번 스크래치는 나를 기진맥진하게 했다.몇 가지 어려움이 있습니다. 잠시 후 게시물에서 해결하겠습니다. 하지만 이 모든 것은 재미있습니다.진정한 좋은 도전은 나로 하여금 그것들을 해결하는 창조적인 방법을 생각하게 했다.
과정 가져오기

This가 나의 출발점이다.나는 거짓말을 할 줄 모른다. 그것은 틀림없이 좀 무섭다.
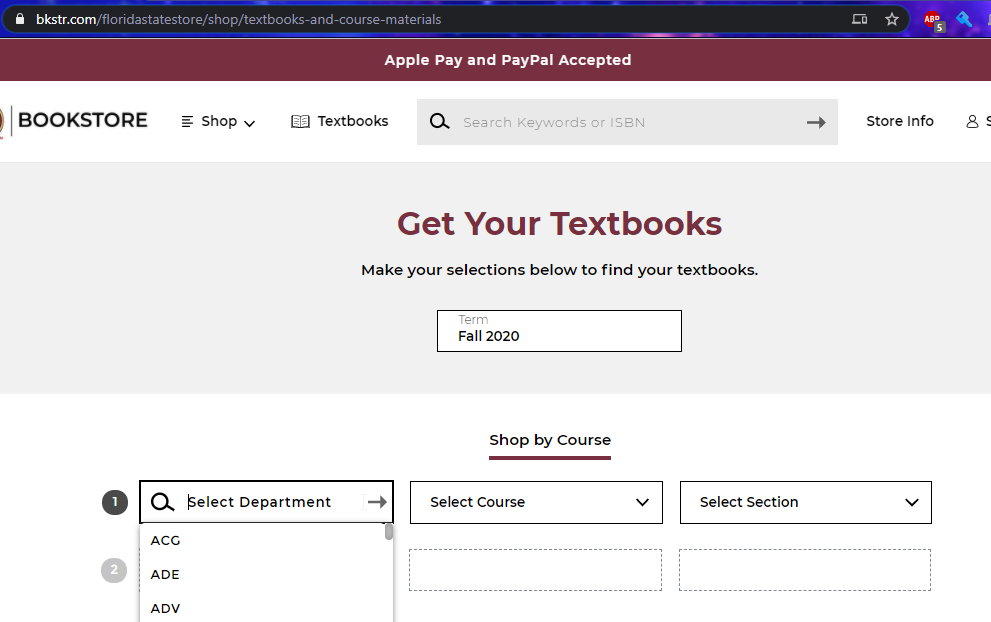
부서과정.그리고 장과 절.여기는 280개의 부서가 있다.나는 모두 몇 개의 장과 절이 있는지 계산해 내지 못했지만, 최종 전체 서적 (숫자와 인쇄판 포함) 은 10736권이다.아직 많은 장과 절이 아무런 필요 없는 재료가 있다.
다행히도, bkstr.com은 현대 사이트인 것 같습니다. Angular 2+를 사용합니다.모든 컨텐츠는 XHR을 통해 로드되고 JSON으로 제공됩니다.그러나 스프레드시트에서 사용할 수 있도록 데이터를 포맷해야 합니다.이 구조가 어떻게 작동하는지 이해하기만 하면 된다.
interface ISection {
courseId: string;
courseRefId: string;
sectionName: string;
};
interface ICourse {
courseName: string;
section: ISection[];
};
interface IDepartment {
depName: string;
course: ICourse[];
};
처음에 저는 부서를 선택할 때 XHR 요청을 관찰했고 프로젝트를 선택한 후에 과정과 일부 데이터를 불러오기를 원했습니다.하지만 없습니다.com 함부로 하지 않습니다.그들은 사전에 이 모든 데이터를 불러왔다.이것은 나에게 있어서 훨씬 쉽다.요청된 JSONhttps://svc.bkstr.com/courseMaterial/courses?storeId=11003&termId=100063052은 다음과 같습니다.
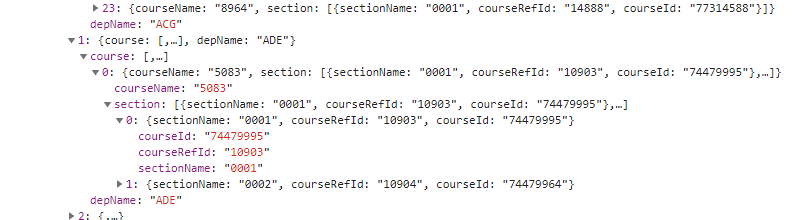
termId는 이곳에서 나에게 매우 의미가 있다.현재 기본값은 2020년 가을이지만, 우리는 그것을 다른 학기로 바꿀 수도 있다.근데...storeId?그리고 잠깐만요.그 도메인 이름은 플로리다와 무관하다.다른 대학이 얼마나 남았어?com 서비스?
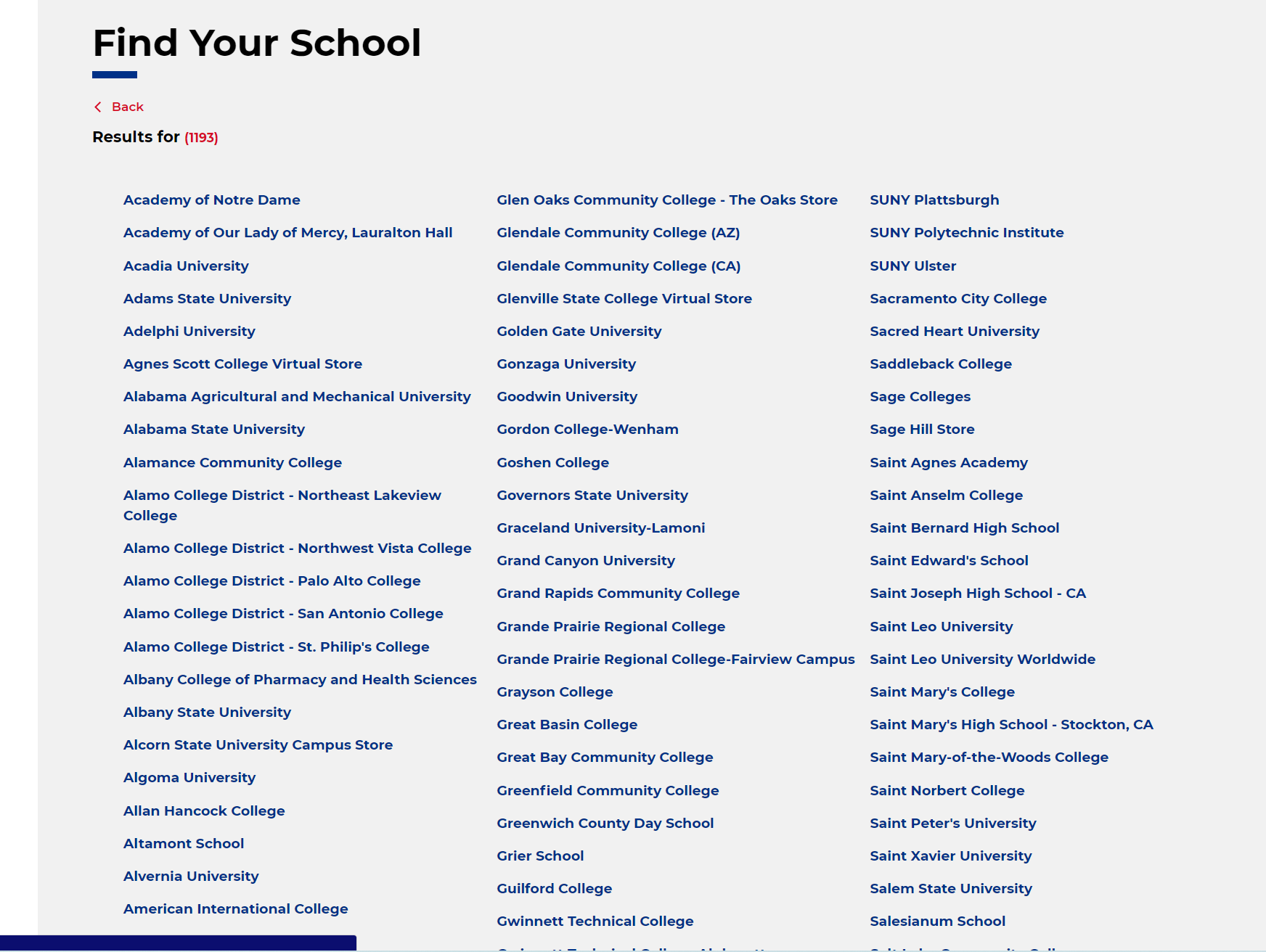
Dang,bkstr.일반 도메인 이름 형식입니다.니가 가.이 명단에는 틀림없이 1000여 개의 학교가 있을 것이다.
나는 해 본 적이 없지만, 나는 네가 storeId와termId로 이 대학들 중 어느 곳과도 교환할 수 있다고 내기를 걸겠다.차갑다
책 정보 얻기

이것은 나의 다음 단계이다.
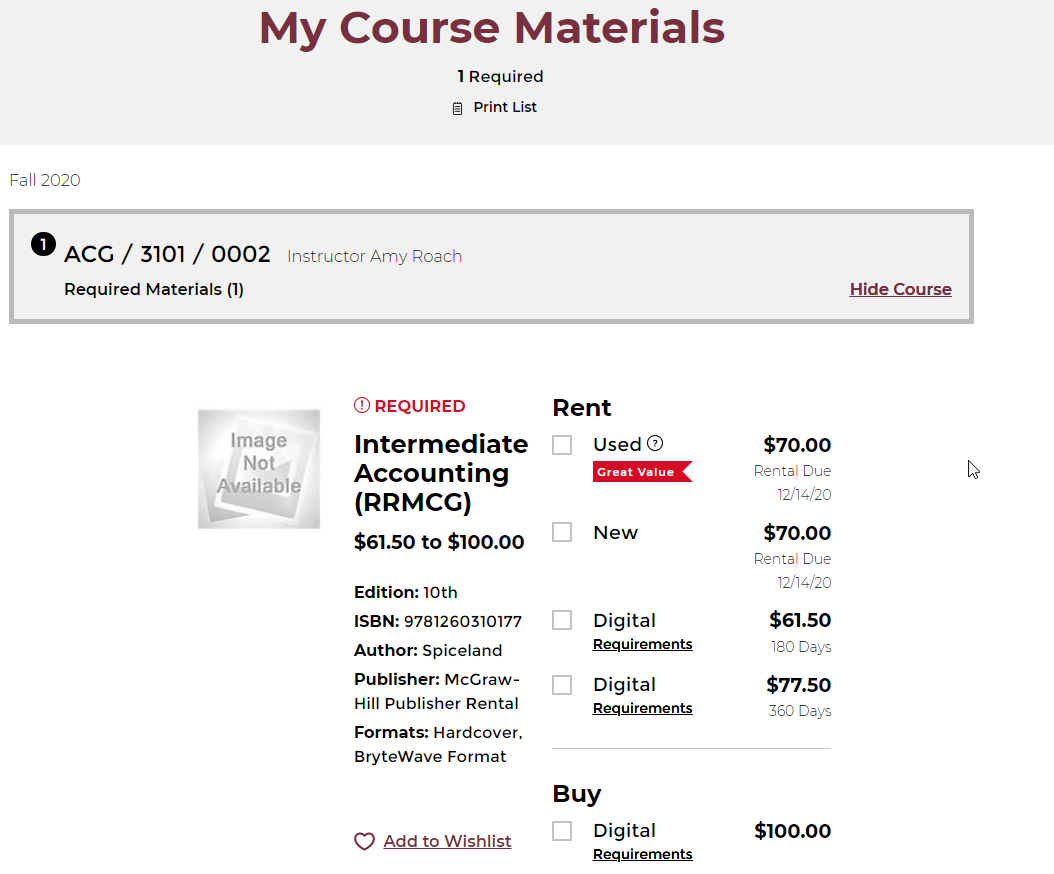
XHR 요청으로 다시 이동하여 표시됨 https://svc.bkstr.com/courseMaterial/results?storeId=11003&langId=-1&catalogId=11077&requestType=DDCSBrowse):
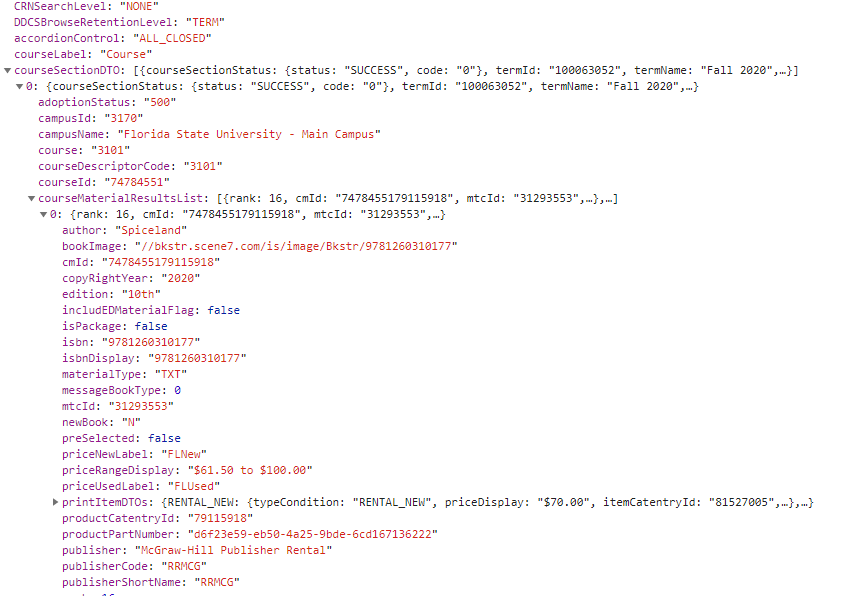
좋아, 나는 장사를 하고 있어.이제 이 정보를 얻기 위해 어떤 정보가 필요한지 봅시다.위의 POST 요청에서 유효 로드를 확인합니다.
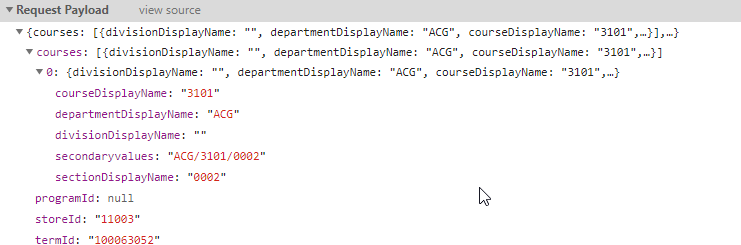
너무 좋아요.나는 위의 부서 전화에서 이 모든 정보를 얻었다.그리고... 다른 재밌는 거 봤어요?
courses 부분은 하나의 수조이다.한 번에 여러 과목을 신청해도 됩니까?플로리다 주립 대학에 280개 학과가 있다면, 학과당 평균 30개 과목(어떤 과목은 500과목을 초과하고, 어떤 과목은 1개를 초과하기 때문에 이것은 매우 대략적인 추정)이다. 그리고 각 과목이 4개 과목(같은 어둠 속에서 촬영된 것)이라고 가정하면, 33600과목을 검사해야 한다.만약 내가 그 중의 일부 요청을 묶을 수 있다면, 스크립트 시간과 전체 부하를 현저히 줄일 것이다.
좋아, 나는 나의 전진의 길이 있어.첫 번째 요청에서 모든 부서, 과정, 장과 절을 얻고 두 번째 요청에서 책 정보를 얻는다.인코딩을 시작하는 시간입니다.
작은 도전

네, 대량의 책이 있을 거라는 것을 알고 있습니다.이 가능하다, ~할 수 있다,...
첫 번째 사이트: 403에서 axios 요청을 보내는 중 오류가 발생했습니다.사용자 에이전트가 추가되었습니다.몇 번의 요청 후에 나는 또 403을 쳤다.내 웹 브라우저에서 복사한 쿠키를 추가했습니다.나는 장사를 하고 있다.이제 다 나았어요.
코드 시작:
const termId = "100063052";
const departments = await getCourses(termId);
console.log('Departments', departments.length);
const courseMaterials: any[] = [];
// Loop through everything
for (let depIndex = 0; depIndex < departments.length; depIndex++) {
const department = departments[depIndex];
const sectionsToRequest: any[] = [];
for (let courseIndex = 0; courseIndex < department.course.length; courseIndex++) {
const course = department.course[courseIndex];
for (let sectionIndex = 0; sectionIndex < course.section.length; sectionIndex++) {
const section = course.section[sectionIndex];
// Create array of sections from course to request all at once
sectionsToRequest.push({
courseDisplayName: course.courseName,
departmentDisplayName: department.depName,
divisionDisplayName: "",
sectionDisplayName: section.sectionName
});
}
}
... // more below
sectionsToRequest 그룹에 추가하고, 이 그룹을 이 URL에 전달하는 것을 보여 주었다.첫 번째 학과(회계학. Pfft, 내 말이 맞습니까? 농담입니다. 내 학위는 회계학입니다.)69개의 수업이 있는데, 몇 개의 수업이 있는지 누가 알겠는가.그리고.. 실패했어요.오류 메시지와 bkstr를 보십시오.com 계속 잘했어요.
{
"errors": [
{
"errorKey": "_ERR_GENERIC",
"errorParameters": [
"DDCS Course Added cannot be greater than 30"
],
"errorMessage": "The following error occurred during processing: \"DDCS Course Added cannot be greater than 30\".",
"errorCode": "CMN0409E"
}
]
}
let courseSectionResults: any;
console.log('Total coursesToRequest', sectionsToRequest.length);
// Can only includes 30 sections per request
const totalRequests = Math.ceil(sectionsToRequest.length / 30);
for (let i = 0; i < totalRequests; i++) {
try {
courseSectionResults = await getCourseMaterials(termId, sectionsToRequest.slice(i * 30, 30));
}
catch (e) {
console.log('Error requesting', e?.response?.status ? e.response.status : e);
throw 'Error here';
}
다음은 우리의 결과를 살펴보고 재료만 추출한 부분입니다.
for (let courseSectionResult of courseSectionResults) {
// Sections that aren't successes don't have materials
if (courseSectionResult.courseSectionStatus?.status === 'SUCCESS') {
더 큰 도전

지금까지 모든 것이 보기에 매우 좋다.나는 첫 번째 부서에서 그것을 운행하는데, 효과가 매우 좋다.280개 부서를 모두 열어줄 때가 됐다.그것은 챔피언처럼 전진한 후에 10-20개 부문을 거쳐... 403.어?나는 과자가 이 문제를 해결할 수 있다고 생각했다.
나는 브라우저에서 웹 사이트로 내비게이션했다.인증 코드 프롬프트.나는 그것을 해결하고 코드를 다시 실행했다.10-20개 부서, 403 및 인증 코드.
빌어먹을, 이제 어떡해.이것은 내가 받은 것addressed beating captchas before이지만, 나는 심지어 이 사이트에 전화를 하지 않았다.나는 인형을 쓰지 않았다.나는 정말 인형 부분을 추가하고 싶지 않다.axios를 사용하여 웹 페이지를 탐색하고 검증 코드를 관찰한 후에 그것을 해결하려고 시도하고 싶지 않다. 만약 그것이 403에 도달한다면.
이제 루미나티 해봐.나는 얼마 전에 그것에 관한 글을 한 편 썼다.이것은 인증 코드를 해결하는 것보다 조금 비싸지만, 그것은 틀림없이 내가 이미 작성한 코드를 더욱 간단하게 할 것이다.
Luminati와 함께 운행합니다.403은 일정 수량의 요청 후에어떻게 된 거야?나는 매우 곤혹스럽다.같은 Luminati를 사용하여 요청post을 전송합니다.내 요청은 에이전트를 사용하고 있습니다.왜 403이야?만약 IP가 회전하고 있다면, 몇 개의 요청 후에 나를 막는 것을 어떻게 알 수 있습니까?나는 지금:
https://lumtest.com/myip.json
나는 잠자리에 들었다.
때때로, 당신은 단지 침대에서 인코딩만 합니까?내가 그랬어.
쿠키
과자쿠키를 기반으로 추적하고 막아야 합니다.나는 과자를 가져갔다.그리고... 403은 없어요.11000권의 책.너무 신기하다
const url = `https://svc.bkstr.com/courseMaterial/courses?storeId=11003&termId=${termId}`;
const axiosResponse = await axios.get(url, {
headers: {
// Don't add a cookie
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
},
proxy: false,
httpsAgent: new HttpsProxyAgent(`https://${process.env.luminatiUsername}:${process.env.luminatiPassword}@zproxy.lum-superproxy.io:22225`)
});
// Don't add a cookie !플랫할 코드
별거 아니에요.
function flattenData(courseMaterial: any, departmentName: string, courseName: string, sectionName: string) {
const materials: any[] = [];
const courseData: any = {
department: departmentName,
course: courseName,
section: sectionName,
author: courseMaterial.author,
bookImage: courseMaterial.bookImage,
edition: courseMaterial.edition,
isbn: courseMaterial.isbn,
title: courseMaterial.title,
publisher: courseMaterial.publisher
};
// for non digital items
if (courseMaterial.printItemDTOs) {
for (let key in courseMaterial.printItemDTOs) {
if (courseMaterial.printItemDTOs.hasOwnProperty(key)) {
const printItem: any = {
...courseData
};
printItem.price = courseMaterial.printItemDTOs[key].priceNumeric;
printItem.forRent = key.toLocaleLowerCase().includes('rent');
printItem.print = true;
materials.push(printItem);
}
}
}
if (courseMaterial.digitalItemDTOs) {
for (let i = 0; i < courseMaterial.digitalItemDTOs.length; i++) {
const digitalItem = {
subscriptionTime: courseMaterial.digitalItemDTOs[0].subscription,
price: courseMaterial.digitalItemDTOs[0].priceNumeric,
print: false,
forRent: true,
...courseData
};
materials.push(digitalItem);
}
}
return materials;
}
courseData 대상을 구축했고 이 항목을 구축할 때 courseData만 포함하고 확산산(대상에 적용!)을 사용했습니다.일하기에 매우 매력적이다.끝났어!
모든 코드
 를 참조하십시오.
를 참조하십시오.여기 있다 업무 단서 찾기?
에서 논의한 기술을 사용하면 우리는 이미 좋은 웹 데이터에 접근하는 방법을 시작할 수 있다.자세한 내용은 를 참조하십시오javascriptwebscrapingguy.com!
게시물Cobalt Intelligence이 먼저 Jordan Scrapes FSU’s Bookstore에 올라왔다.
Reference
이 문제에 관하여(조던은 플로리다 주립 대학 서점에 있다), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://dev.to/aarmora/jordan-scrapes-fsu-s-bookstore-5dac텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
