오픈 소스 검색 엔진 juhu를 소개합니다
내 제출물 개요
Juhu는 Nodejs 및 Redis 데이터베이스를 사용하여 구축된 오픈 소스 검색 엔진입니다. 웹 사이트의 사용 사례 시나리오를 이미 짐작했듯이. 직접 해보시면 어떨까요, Search for Elon Musk .
저는 항상 검색 엔진이 어떻게 만들어지는지, 가장 중요한 것은 SEO가 어떻게 이루어지는지 알고 싶었습니다. 새로운 검색 엔진을 구축하는 여정을 통해 데이터가 웹 사이트에 표시되는 방식, 크롤러가 웹 사이트의 모든 내용을 이해하는 데 필요한 HTML 태그가 무엇인지에 대해 많은 것을 배웠습니다. 또한 미리 스타일이 지정된 HTML 요소(특정 목적을 위해 빌드됨)를 사용하는 것이 나중에 요소의 스타일을 지정하기 위해 CSS를 사용하는 것보다 낫습니다.
제출 카테고리:
MEAN/MERN Mavericks 예, MERN을 사용했으며 M도 R로 대체했습니다. 기본 데이터베이스로 redis를 사용했음을 의미합니다.
내 프로젝트의 비디오 설명자
사용 언어:
Javascript를 기본 언어로 사용하고 Nodejs를 런타임 환경으로 사용했습니다. 이 응용 프로그램을 빌드하기 위해 다른 라이브러리/패키지를 사용했습니다. 그들 중 일부는 다음과 같습니다.
코드 링크
MERN 애플리케이션 저장소:
아시시판티 / 검색 엔진
이것은 redis와 puppeteer를 사용하여 구축된 오픈 소스 검색 엔진입니다.
Juhu - 검색 엔진
Juhu는 사용자를 추적하지 않는 오픈 소스 검색 엔진이며 사용자 정의가 가능한 ID입니다.



개요 비디오
다음은 프로젝트와 프로젝트에서 Redis를 사용하는 방법을 설명하는 짧은 비디오입니다.
작동 방식
우선 모든 봇은 다른 웹사이트를 통해 실행하는 데 사용되며 해당 봇은 URL이 크롤링할 수 있는지 여부를 확인합니다. 크롤링할 수 있으면 인덱싱할 수 있음을 의미합니다. 따라서 봇은 해당 웹사이트에서 데이터를 스크랩합니다. 데이터를 필터링하여 스크랩한 데이터를 보다 쉽게 검색하고 인덱싱할 수 있는 형태로 저장합니다. 내가 말한 내용을 정리하기 위해 여기에 약간의 아키텍처 다이어그램을 첨부하고 싶습니다.

데이터 저장 방법:
우선 우리 서버는 redis 데이터베이스와 연결되어야 합니다. 이것은 긴 코드이지만 작동합니다 :).
import { Client }
…
View on GitHub
봇 저장소:
아시시판티
/
웹 크롤러
웹 크롤러
이것은 javascript의 puppeteer 라이브러리를 사용하여 만든 웹 크롤러입니다. 그것은 다른 웹사이트를 방문하고 정보를 스크랩하고 검색 엔진에서 액세스할 수 있는 데이터베이스 내부에 정보를 저장합니다.
View on GitHub
건축물:
연결:


다음은 프로젝트와 프로젝트에서 Redis를 사용하는 방법을 설명하는 짧은 비디오입니다.
작동 방식
우선 모든 봇은 다른 웹사이트를 통해 실행하는 데 사용되며 해당 봇은 URL이 크롤링할 수 있는지 여부를 확인합니다. 크롤링할 수 있으면 인덱싱할 수 있음을 의미합니다. 따라서 봇은 해당 웹사이트에서 데이터를 스크랩합니다. 데이터를 필터링하여 스크랩한 데이터를 보다 쉽게 검색하고 인덱싱할 수 있는 형태로 저장합니다. 내가 말한 내용을 정리하기 위해 여기에 약간의 아키텍처 다이어그램을 첨부하고 싶습니다.

데이터 저장 방법:
우선 우리 서버는 redis 데이터베이스와 연결되어야 합니다. 이것은 긴 코드이지만 작동합니다 :).
import { Client }…
View on GitHub
봇 저장소:
아시시판티 / 웹 크롤러
웹 크롤러
이것은 javascript의 puppeteer 라이브러리를 사용하여 만든 웹 크롤러입니다. 그것은 다른 웹사이트를 방문하고 정보를 스크랩하고 검색 엔진에서 액세스할 수 있는 데이터베이스 내부에 정보를 저장합니다.
View on GitHub
건축물:
연결:
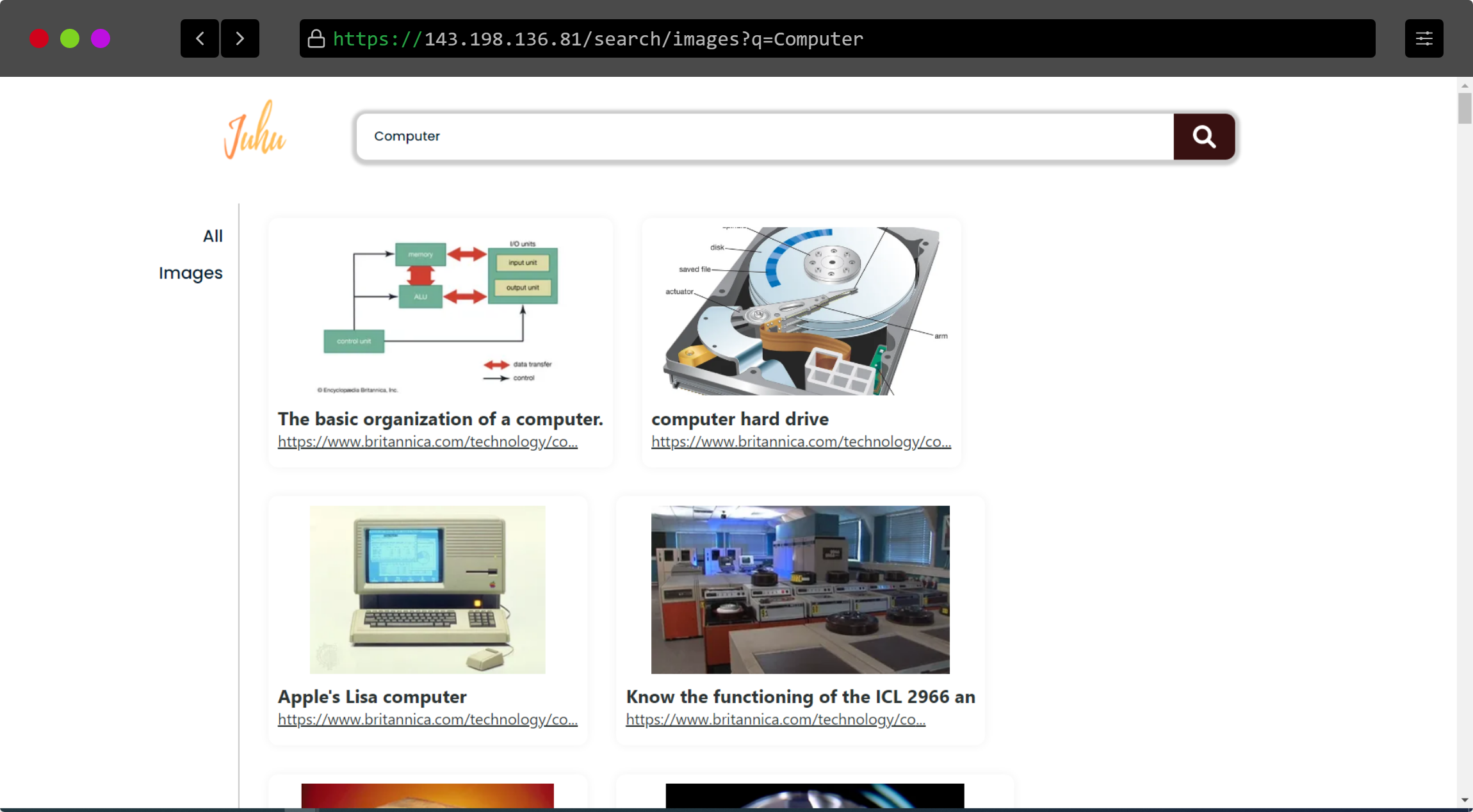
홈페이지 일부 스크린샷


협력자
그리고 나
Reference
이 문제에 관하여(오픈 소스 검색 엔진 juhu를 소개합니다), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://dev.to/aashishpanthi/introducing-juhu-an-open-source-search-engine-268i텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
