Forestplot을 사용하여 Python에서 계수 플롯 만들기
20147 단어 opensourcedatasciencepythonanalytics
Forestplot 패키지를 사용하여 신뢰 구간으로 추정치를 그리는 방법을 보여줍니다.이 패키지는 업스트림 분석의 상관 계수 또는 회귀 추정치를 표시합니다(this example of correlation analysis 참조).
패키지 준비 및 데이터 로드
PyPI에서 패키지를 설치하려면:
pip install forestplot
특정 요소가 수면 시간과 어떻게 관련되는지 보고하는 예제 데이터 세트를 로드합니다.
import forestplot as fp
df = fp.load_data("sleep") # companion example data
df.head(3)
바르
아르 자형
오류
상표
그룹
ll
헐
N
힘
p-값
0
나이
0.0903729
0.0696271
몇년에 걸쳐
나이
0.02
0.16
706
0.67
0.0163089
1
검은색
-0.0270573
0.0770573
검은색인 경우 =1
기타 요인
-0.1
0.05
706
0.11
0.472889
2
목사
0.0480811
0.0719189
사무직이면 =1
직업
-0.03
0.12
706
0.25
0.201948
위의
dataframe에서 각 행은 특성과 밤에 취하는 수면의 양을 상관시키는 해당 상관 계수를 갖는 개별 특성입니다.예를 들어 상관 계수가
age 인 첫 번째 행 0.09 (p = 0.016) 은 나이가 많은 사람들이 더 많은 수면을 취하는 것을 나타냅니다.(상관 계수가 실제
sleep75.csv 데이터에서 어떻게 계산되는지 확인하려면 this notebook을 참조하십시오.)추정치를 플로팅합니다.
포레스트 플롯(또는 계수 플롯, 점 플롯, 계수 플롯)은 추정치와 신뢰 구간을 시각화하는 데 유용합니다.
df의 추정치를 플로팅하려면 다음을 수행하십시오.fp.forestplot(df, # the dataframe with results data
estimate="r", # col containing estimated effect size
ll="ll", hl="hl", # columns containing conf. int. lower and higher limits
varlabel="label", # column containing variable label
ylabel="Confidence interval", # y-label title
xlabel="Pearson correlation" # x-label title
)

특수효과 맞춤설정 및 추가(Pt. 1)
변수 그룹 소제목(예: 노동 요소 소제목)을 추가하고 추정치를 정렬(그룹 내에서)할 수 있습니다. 변수 그룹 부제목(
group_order )의 순서를 정렬할 수도 있습니다.fp.forestplot(df, # the dataframe with results data
estimate="r", # col containing estimated effect size
moerror="moerror", # columns containing conf. int. margin of error
varlabel="label", # column containing variable label
groupvar="group", # Add variable groupings
# group ordering
group_order=["labor factors", "occupation", "age", "health factors",
"family factors", "area of residence", "other factors"],
sort=True # sort in ascending order (sorts within group if group is specified)
)

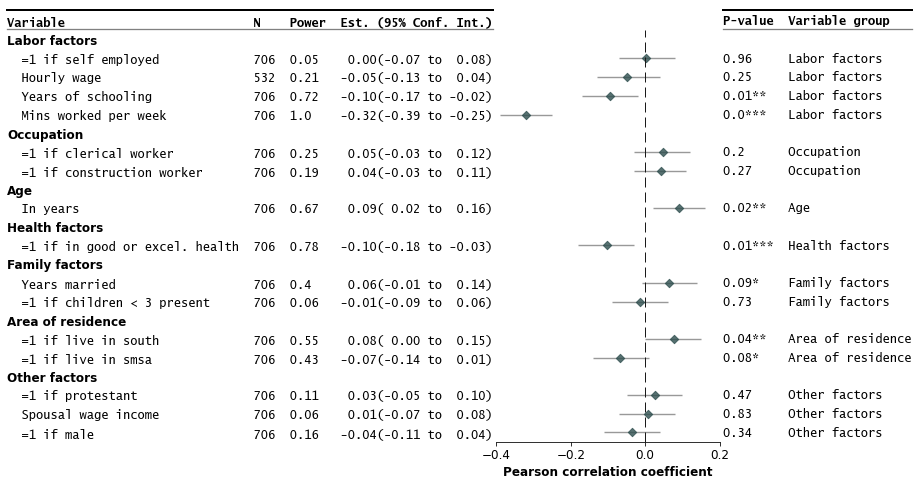
특수효과 맞춤설정 및 추가(Pt. 2)
샘플 크기(예:
N 및 formatted_pval )와 같은 플롯에 더 많은 주석을 추가하고 테이블 라인을 추가할 수도 있습니다.fp.forestplot(df, # the dataframe with results data
estimate="r", # col containing estimated effect size
ll="ll", hl="hl", # lower & higher limits of conf. int.
varlabel="label", # column containing the varlabels to be printed on far left
pval="p-val", # column containing p-values to be formatted
annote=["n", "power", "est_ci"], # columns to report on left of plot
annoteheaders=["N", "Power", "Est. (95% Conf. Int.)"], # ^corresponding headers
rightannote=["formatted_pval", "group"], # columns to report on right of plot
right_annoteheaders=["P-value", "Variable group"], # ^corresponding headers
groupvar="group", # column containing group labels
group_order=["labor factors", "occupation", "age", "health factors",
"family factors", "area of residence", "other factors"],
xlabel="Pearson correlation coefficient", # x-label title
xticks=[-.4,-.2,0, .2], # x-ticks to be printed
sort=True, # sort estimates in ascending order
table=True, # Format as a table
# Additional kwargs for customizations
**{"marker": "D", # set maker symbol as diamond
"markersize": 35, # adjust marker size
"xlinestyle": (0, (10, 5)), # long dash for x-reference line
"xlinecolor": ".1", # gray color for x-reference line
"xtick_size": 12, # adjust x-ticker fontsize
}
)

최종 발언
계획된 향후 개선 사항에는 플롯의 행당 여러 추정을 허용하는 것이 포함됩니다.
삼림 플롯에는 많은 별칭이 있습니다. 다른 이름으로는 coefplots, 계수 도표, 메타 분석 도표, 도트 도표, 점과 위스커 도표, 블로보그램, 여백 도표, 회귀 도표 및 로프사다리 도표가 있습니다.
이 게시물을 통해 제
forestplot 패키지에 대한 가시성을 얻을 수 있기를 바랍니다. 동시에 API의 사용 용이성과 기능에 대한 의견을 듣게 되어 기쁩니다. 구성. 자세한 내용은 the GitHub repo readme을 참조하십시오.LSYS / 삼림 플롯
출판 준비가 되었지만 사용자 정의가 가능한 포레스트 플롯(coefplots)을 만드는 Python 패키지입니다.
삼림도

삼림 플롯을 위한 간편한 API.
출판 준비가 되었지만 사용자 지정이 가능한 포레스트 플롯을 만드는 Python 패키지
이 패키지를 사용하면 바로 사용할 수 있는 포리스트 플롯을 쉽게 만들 수 있습니다. 사용자는 dataframe(예: 스프레드시트에서)를 제공합니다. 여기서 행은 추정치, 변수 레이블, 신뢰 구간 하한 및 상한을 포함하는 열이 있는 변수/연구에 해당합니다.
추가 옵션을 사용하면 플롯의 주석으로 dataframe의 열을 쉽게 추가할 수 있습니다.
풀어 주다


상태


적용 범위

파이썬

문서


메타





목차
설치
PyPI에서 설치
pip install forestplot
소스에서 설치
git clone https://github.com/LSYS/forestplot.git
cd forestplot
pip install .
( back to top )
빠른 시작
import forestplot as fp
df = fp.load_data("sleep") # companion example data
df.head(3)
바르
아르 자형
오류
상표
그룹
ll
헐
N
…
View on GitHub
Reference
이 문제에 관하여(Forestplot을 사용하여 Python에서 계수 플롯 만들기), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다
https://dev.to/lsys/making-coefficient-plots-in-python-using-forestplot-7i7
텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
Reference
이 문제에 관하여(Forestplot을 사용하여 Python에서 계수 플롯 만들기), 우리는 이곳에서 더 많은 자료를 발견하고 링크를 클릭하여 보았다 https://dev.to/lsys/making-coefficient-plots-in-python-using-forestplot-7i7텍스트를 자유롭게 공유하거나 복사할 수 있습니다.하지만 이 문서의 URL은 참조 URL로 남겨 두십시오.
![]() 우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
우수한 개발자 콘텐츠 발견에 전념
(Collection and Share based on the CC Protocol.)
좋은 웹페이지 즐겨찾기
